模块概述
LangChat Pro 的向量化模块是 RAG(Retrieval-Augmented Generation)系统的核心组件,负责将文档内容转换为高维向量数据,并存储到向量数据库中,为知识库检索和问答提供语义搜索能力。RAG 业务流程
向量化主要强调的 RAG 的业务流程,他有如下步骤:- 知识库上传文档文件
- Java 代码解析文档文件生成文本信息(文本字符串)
- 通过向量模型将文本信息转换成高纬度向量数据
- 将高纬度向量输出存储到向量数据库中
整体架构图
Copy
文档上传 → 文档解析 → 文本分段 → 向量化 → 向量存储 → 语义检索
文档上传处理
前端实现
前端可以看知识库导入这个案例: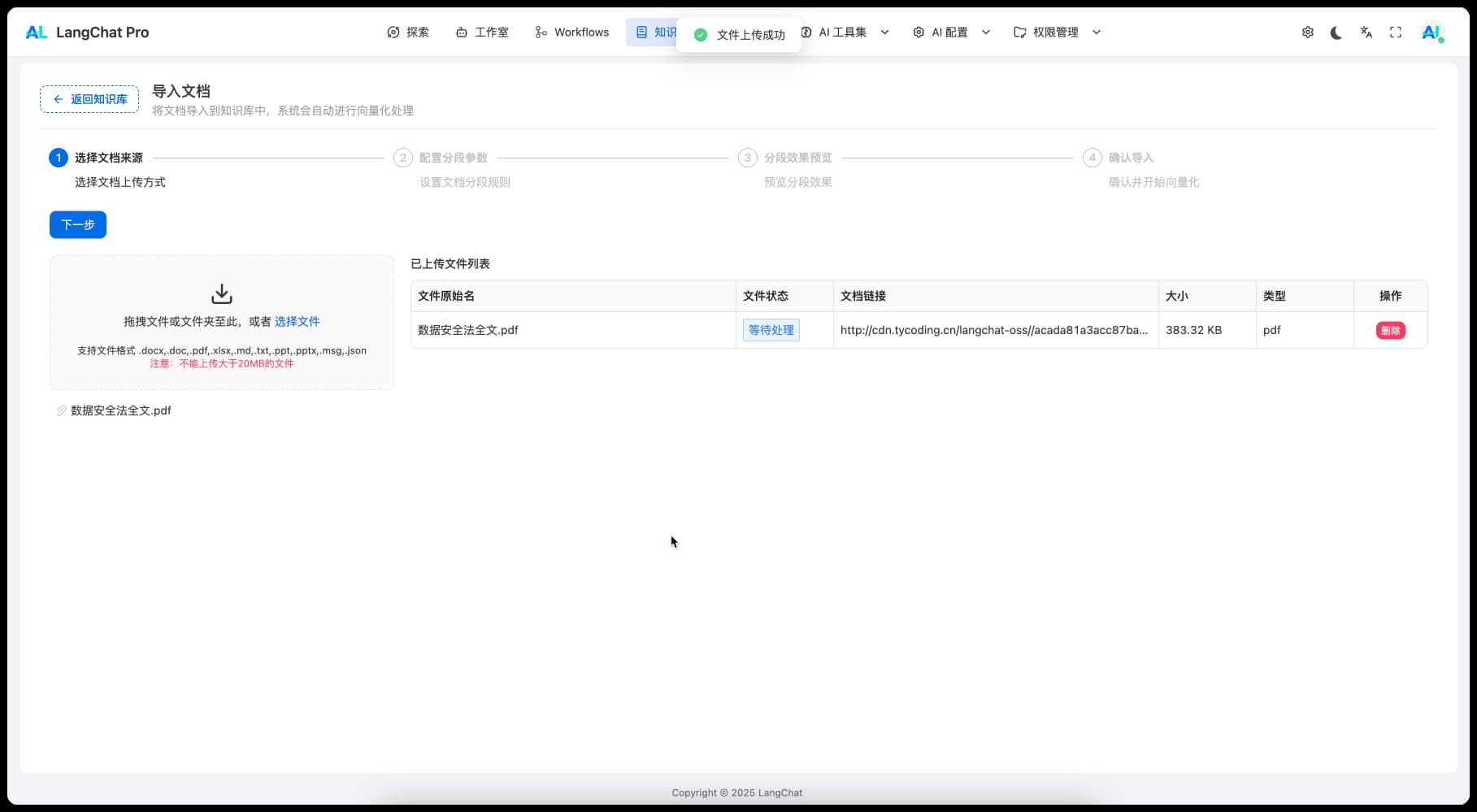
后端接口实现
上述文档上传接口代码如下: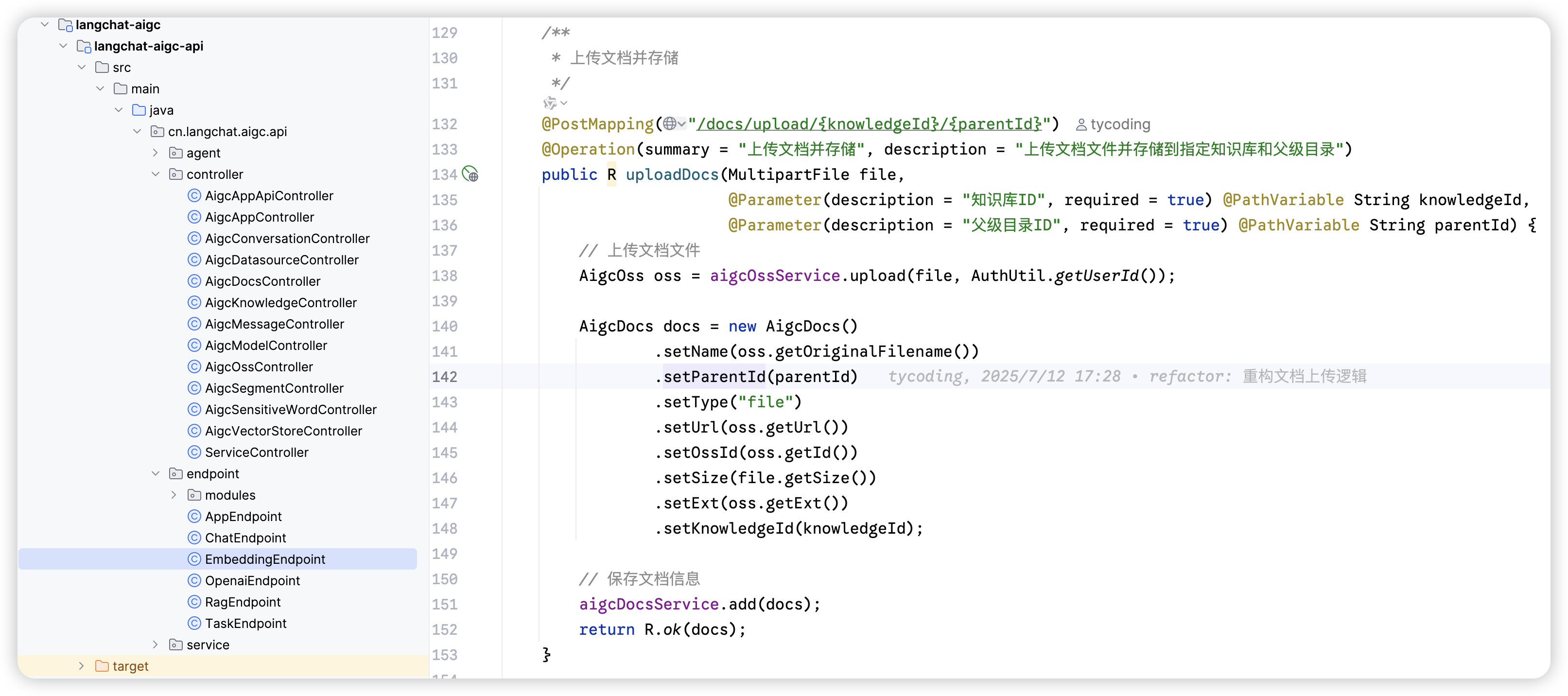 这里首先会将文档文件存储到 OSS(如果 OSS 配置错误,就会直接导致文档上传失败)
这里首先会将文档文件存储到 OSS(如果 OSS 配置错误,就会直接导致文档上传失败)
确保 OSS 配置正确,否则文档上传功能将无法正常工作。
文档分段策略
分段预览功能
我们提供了对上传文档进行不同分段策略的预览功能: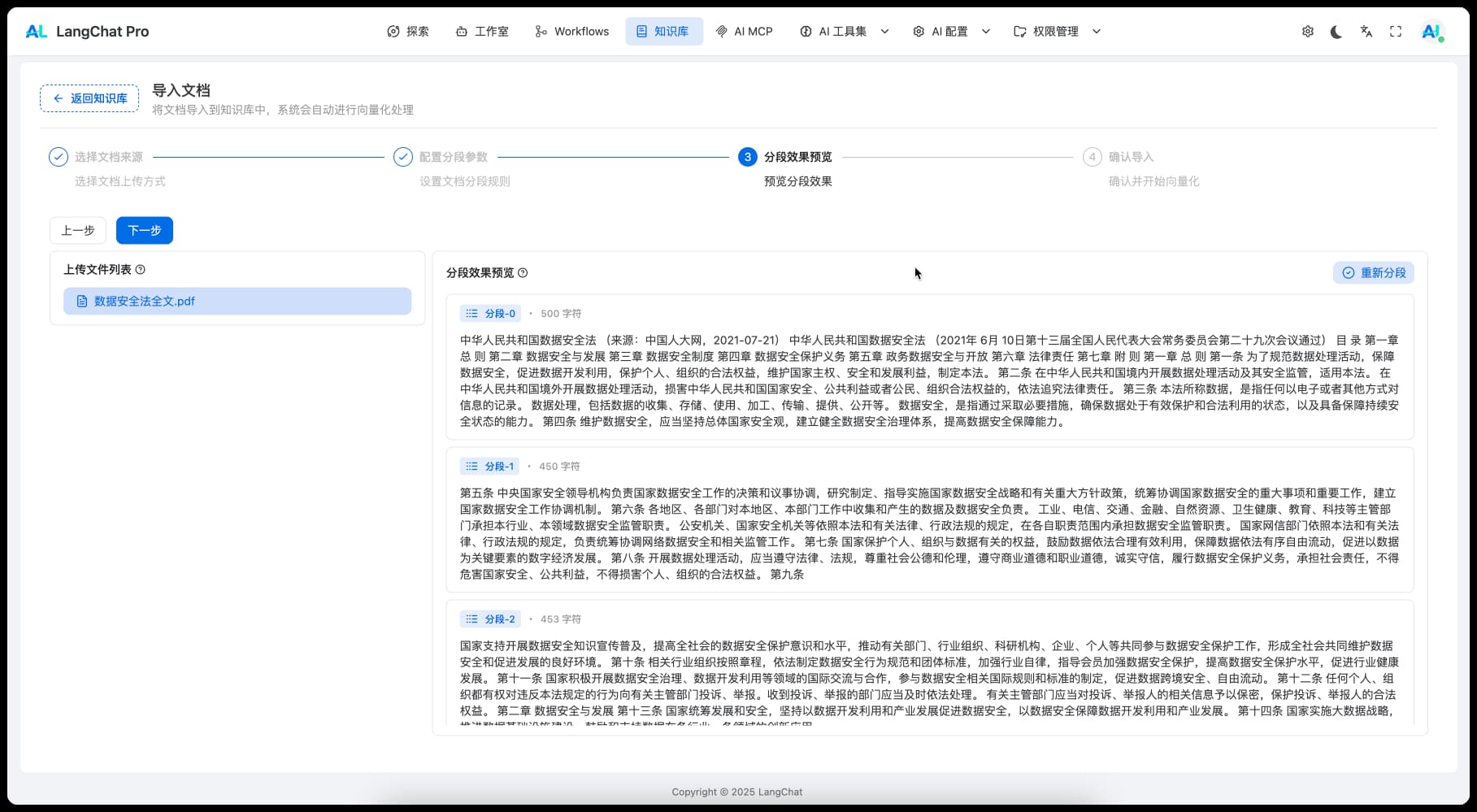
分段策略配置
后端分段接口
文本的分段对应的后端接口如下: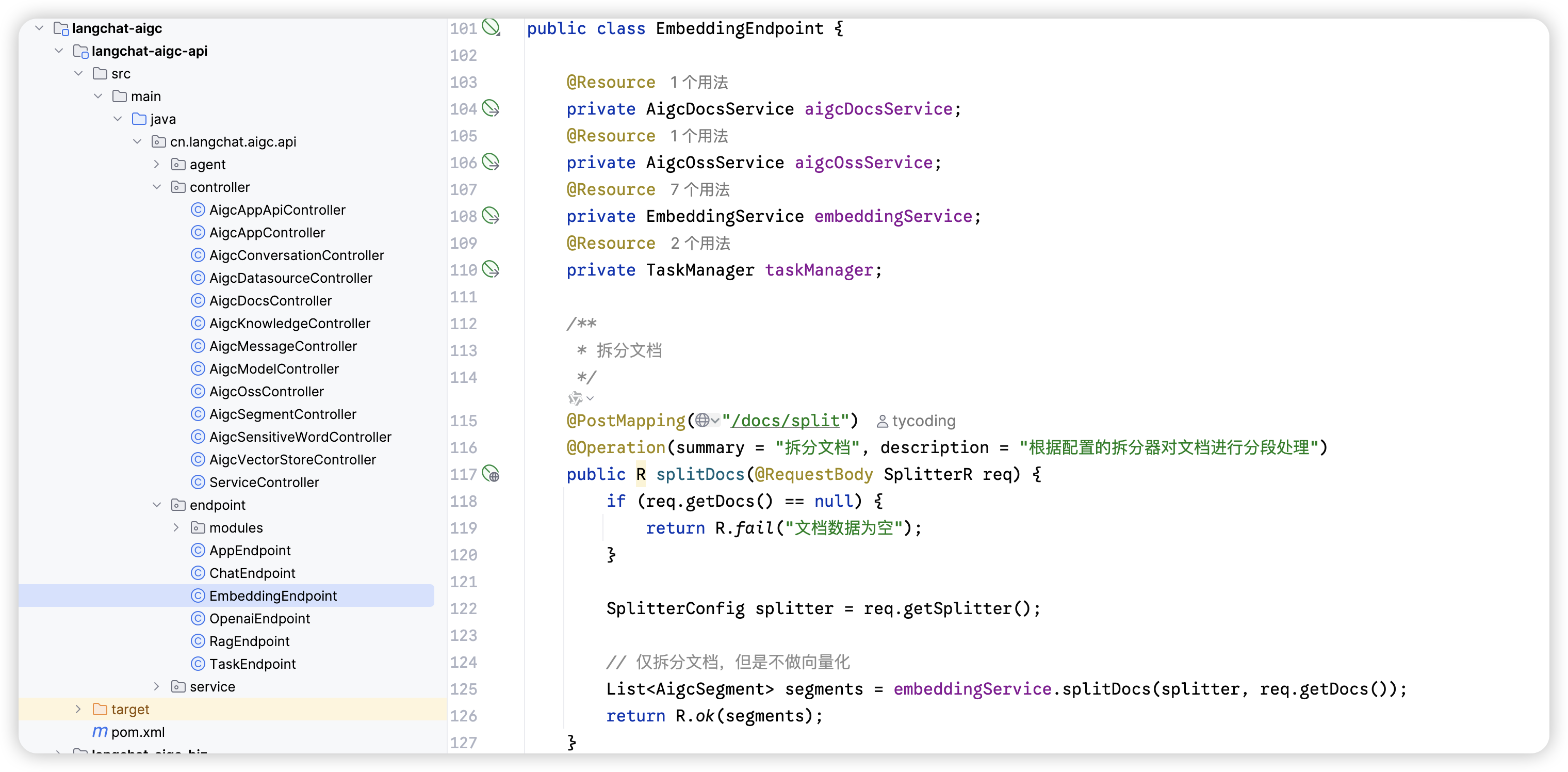
向量化处理
业务实现代码
这个接口对应的业务实现代码如下: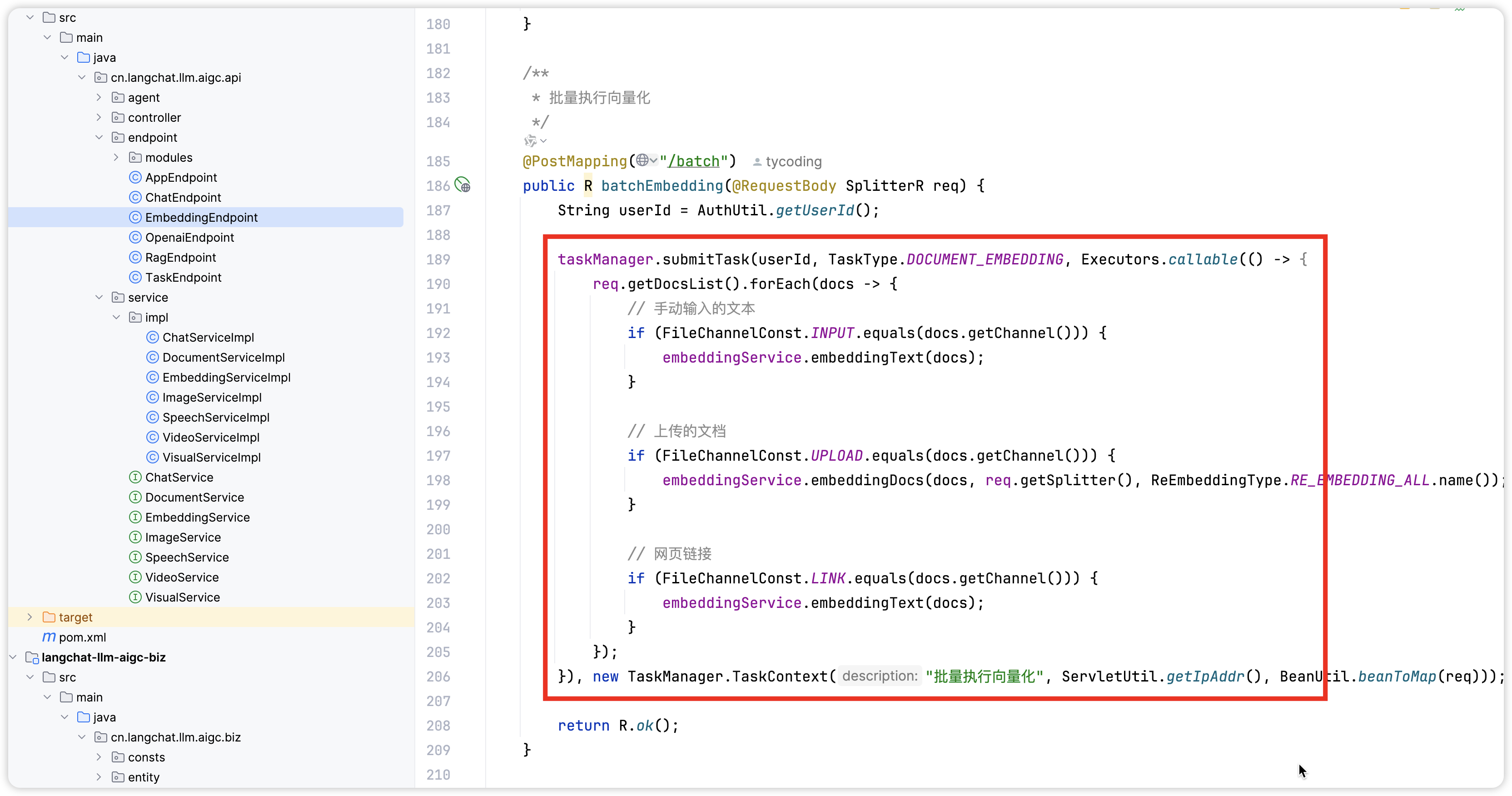 其中核心的向量化解析函数如下:
其中核心的向量化解析函数如下:
Copy
// 向量化文档
List<EmbeddingR> textSegments = langEmbeddingService.embeddingDocs(docs, splitList);
核心实现代码
核心实现代码如下: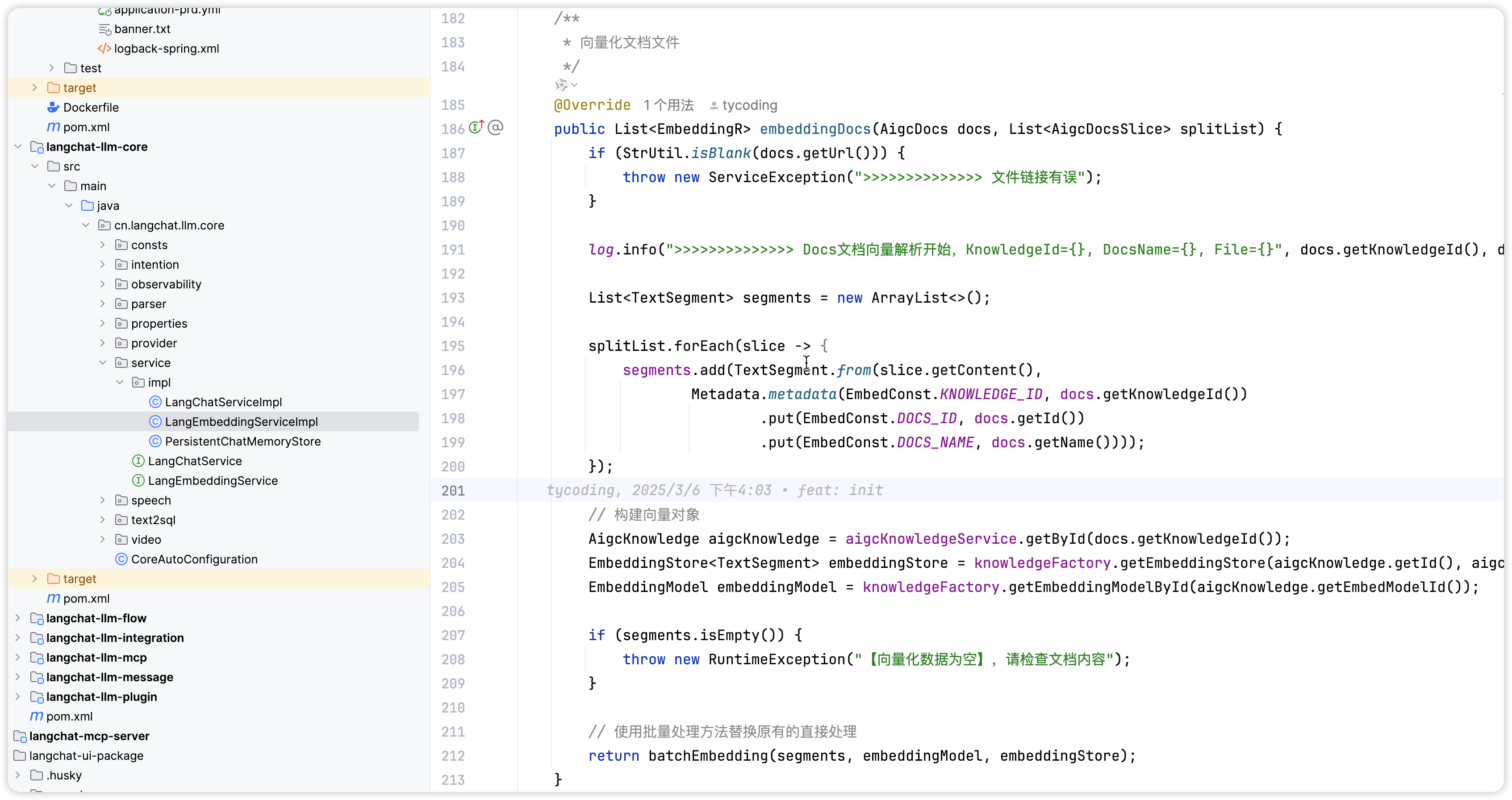
详细实现分析
向量化服务接口
Copy
@Service
public interface LangEmbeddingService {
/**
* 批量向量化文档
* @param docs 文档列表
* @param splitList 分段列表
* @return 向量化结果
*/
List<EmbeddingR> embeddingDocs(List<Document> docs, List<TextSegment> splitList);
/**
* 单个文本向量化
* @param text 文本内容
* @return 向量化结果
*/
EmbeddingR embeddingText(String text);
/**
* 批量文本向量化
* @param texts 文本列表
* @return 向量化结果列表
*/
List<EmbeddingR> embeddingTexts(List<String> texts);
}
向量化服务实现
Copy
@Service
@Slf4j
public class LangEmbeddingServiceImpl implements LangEmbeddingService {
@Autowired
private EmbeddingModelService embeddingModelService;
@Autowired
private VectorDatabaseService vectorDatabaseService;
@Override
@Transactional(rollbackFor = Exception.class)
public List<EmbeddingR> embeddingDocs(List<Document> docs, List<TextSegment> splitList) {
log.info("开始向量化文档,文档数量: {}, 分段数量: {}", docs.size(), splitList.size());
try {
// 1. 验证分段数据
validateSegments(splitList);
// 2. 构建文本分段对象
List<TextSegment> segments = buildTextSegments(docs, splitList);
// 3. 批量向量化
List<EmbeddingR> embeddings = batchEmbedding(segments);
// 4. 存储到向量数据库
saveToVectorDatabase(embeddings);
log.info("文档向量化完成,成功处理 {} 个分段", embeddings.size());
return embeddings;
} catch (Exception e) {
log.error("文档向量化失败: {}", e.getMessage(), e);
throw new EmbeddingException("文档向量化失败", e);
}
}
private List<TextSegment> buildTextSegments(List<Document> docs, List<TextSegment> splitList) {
List<TextSegment> segments = new ArrayList<>();
for (TextSegment split : splitList) {
// 查找对应的文档
Document doc = findDocumentById(docs, split.getDocumentId());
if (doc == null) {
log.warn("未找到文档: {}", split.getDocumentId());
continue;
}
// 构建文本分段对象
TextSegment segment = TextSegment.builder()
.id(split.getId())
.documentId(doc.getId())
.content(split.getContent())
.metadata(buildMetadata(doc, split))
.build();
segments.add(segment);
}
return segments;
}
private List<EmbeddingR> batchEmbedding(List<TextSegment> segments) {
List<EmbeddingR> embeddings = new ArrayList<>();
// 分批处理,避免单次请求过大
int batchSize = 100;
for (int i = 0; i < segments.size(); i += batchSize) {
int end = Math.min(i + batchSize, segments.size());
List<TextSegment> batch = segments.subList(i, end);
// 调用向量模型服务
List<EmbeddingR> batchEmbeddings = embeddingModelService.embeddingBatch(batch);
embeddings.addAll(batchEmbeddings);
log.debug("完成第 {} 批向量化,处理 {} 个分段", (i / batchSize) + 1, batch.size());
}
return embeddings;
}
private void saveToVectorDatabase(List<EmbeddingR> embeddings) {
// 存储到向量数据库
vectorDatabaseService.batchInsert(embeddings);
// 更新分段状态
updateSegmentStatus(embeddings);
}
}
向量模型集成
支持的向量模型
向量模型配置
Copy
langchat:
embedding:
# 默认向量模型
default-model: bge-large-zh-v1.5
# 模型配置
models:
bge-large-zh-v1.5:
provider: huggingface
model-name: BAAI/bge-large-zh-v1.5
dimension: 1024
max-length: 512
batch-size: 32
text-embedding-ada-002:
provider: openai
model-name: text-embedding-ada-002
dimension: 1536
max-length: 8191
batch-size: 100
向量数据库集成
支持的向量数据库
向量数据库配置
Copy
langchat:
vector-database:
# 默认向量数据库
default-provider: pgvector
# 数据库配置
pgvector:
host: localhost
port: 5432
database: langchat
username: postgres
password: password
schema: public
table-prefix: vec_
elasticsearch:
hosts: localhost:9200
username: elastic
password: password
index-prefix: langchat_
性能优化策略
1. 批量处理优化
Copy
@Service
public class EmbeddingService {
// 使用线程池进行并发处理
@Autowired
private ThreadPoolTaskExecutor embeddingExecutor;
public List<EmbeddingR> batchEmbedding(List<TextSegment> segments) {
// 分批处理
List<List<TextSegment>> batches = splitIntoBatches(segments, 100);
// 并发执行
List<CompletableFuture<List<EmbeddingR>>> futures = batches.stream()
.map(batch -> CompletableFuture.supplyAsync(() ->
embeddingModelService.embeddingBatch(batch), embeddingExecutor))
.collect(Collectors.toList());
// 等待所有任务完成
return futures.stream()
.map(CompletableFuture::join)
.flatMap(List::stream)
.collect(Collectors.toList());
}
}
2. 缓存策略
Copy
@Service
public class EmbeddingService {
@Cacheable(value = "text_embeddings", key = "#text.hashCode()")
public EmbeddingR embeddingText(String text) {
// 向量化处理
return embeddingModelService.embedding(text);
}
@CacheEvict(value = "text_embeddings", allEntries = true)
public void clearCache() {
// 清除缓存
}
}
3. 异步处理
Copy
@Service
public class DocumentService {
@Async
public CompletableFuture<Void> processDocumentAsync(Document document) {
try {
// 异步处理文档
processDocument(document);
return CompletableFuture.completedFuture(null);
} catch (Exception e) {
return CompletableFuture.failedFuture(e);
}
}
}
监控和日志
性能监控
- 向量化处理时间监控
- 向量化成功率统计
- 向量数据库性能监控
- 内存和 CPU 使用率监控
业务日志
Copy
@Slf4j
@Service
public class EmbeddingService {
public List<EmbeddingR> embeddingDocs(List<Document> docs, List<TextSegment> splitList) {
long startTime = System.currentTimeMillis();
try {
// 向量化处理
List<EmbeddingR> result = doEmbedding(docs, splitList);
long duration = System.currentTimeMillis() - startTime;
log.info("文档向量化完成,处理 {} 个分段,耗时 {}ms",
splitList.size(), duration);
return result;
} catch (Exception e) {
long duration = System.currentTimeMillis() - startTime;
log.error("文档向量化失败,处理 {} 个分段,耗时 {}ms,错误: {}",
splitList.size(), duration, e.getMessage(), e);
throw e;
}
}
}
错误处理和重试
异常分类
-
模型调用异常
- 网络连接失败
- 模型服务不可用
- 模型参数错误
-
向量数据库异常
- 连接失败
- 存储空间不足
- 索引创建失败
-
业务逻辑异常
- 文档格式不支持
- 分段策略错误
- 权限验证失败
重试机制
Copy
@Service
public class EmbeddingService {
@Retryable(value = {EmbeddingException.class}, maxAttempts = 3, backoff = @Backoff(delay = 1000))
public EmbeddingR embeddingText(String text) {
try {
return embeddingModelService.embedding(text);
} catch (Exception e) {
log.warn("向量化失败,将进行重试: {}", e.getMessage());
throw new EmbeddingException("向量化失败", e);
}
}
@Recover
public EmbeddingR recoverEmbedding(EmbeddingException e, String text) {
log.error("向量化重试失败,使用默认向量: {}", e.getMessage());
// 返回默认向量或抛出异常
return getDefaultEmbedding();
}
}
通过以上架构设计,向量化模块实现了高效、可靠的文档向量化功能,为 RAG 系统提供了强大的语义搜索能力。