
概述
LangChat Pro 提供「可视化模型配置」,支持多家模型供应商与多类型 AI 能力,配置后即可即时生效,便于在工作流与 Agent 中直接使用。
入口:AI 配置 -> 模型配置
是否需要配置模型BaseUrl
我们放开所有模型配置的BaseUrl参数,但是并不是所有模型都需要配置此参数(除非你非常确认API地址,否则不要随意修改此参数)
在LangChat Pro系统中,内置的SDK有几种厂商:
- 阿里云dashscope-sdk
- 百度千帆
- 智谱sdk
BaseUrl 参数。
但是为什么无需填写你们的系统不隐藏掉此参数?因为存在一种场景:阿里云分百炼分为了:国内站和国际站,SDK默认使用的国内站点,国际站点则需要设置BaseUrl参数 其他的厂商,特别是私有化的模型,一定需要配置BaseUrl参数。
支持的模型供应商
- OpenAI
- 阿里云百炼
- GiteeAI
- Xinference
- Ollama
- 硅基流动
- 深度求索
- 智谱 AI
- 百度云千帆
- 火山引擎
如果没有找到适配的供应商,可优先按照 OpenAI 协议进行接入(多数厂商兼容 OpenAI API 规范)。
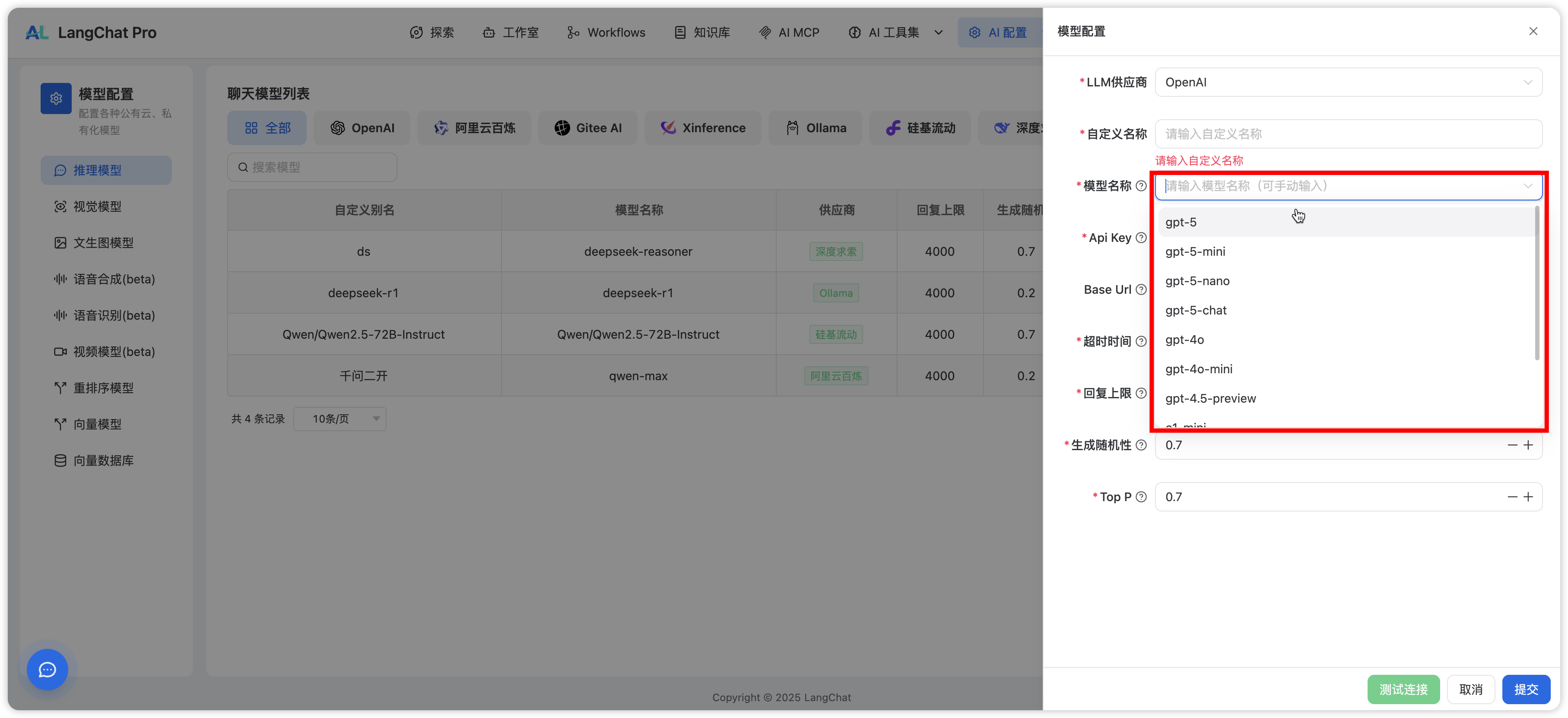
模型版本选择
若下拉框中没有想要的模型版本:- 在下拉框输入目标模型名称;
- 按回车确认;
- 将自动选中为自定义输入的版本。
模型类型
LangChat Pro 支持多种模型能力,常见类型如下:- 推理模型(聊天对话)
- 视觉模型(图像理解/识别)
- 文生图模型(文本生成图像)
- 语音合成(TTS:文字转语音)
- 语音识别(ASR:语音转文本)
- 视频模型(文本生成视频)
- 重排序模型(RAG 排序)
- 向量模型(Embedding)
各模型的配置项基本一致。根据供应商要求填写密钥、接口地址、模型名称等信息即可。
向量数据库(RAG)
在 RAG 场景中,向量数据库用于存储文本向量并支持高效检索。LangChat Pro 目前内置以下适配:- Redis
- PgVector
- Milvus
- Elasticsearch
选择向量库时可根据数据量规模、性能与维护成本综合评估。