
本页面为独立的功能模块,主要用于测试与验证多模态模型的语音合成(Text-to-Speech, TTS)能力,不与其他业务模块耦合。
概述
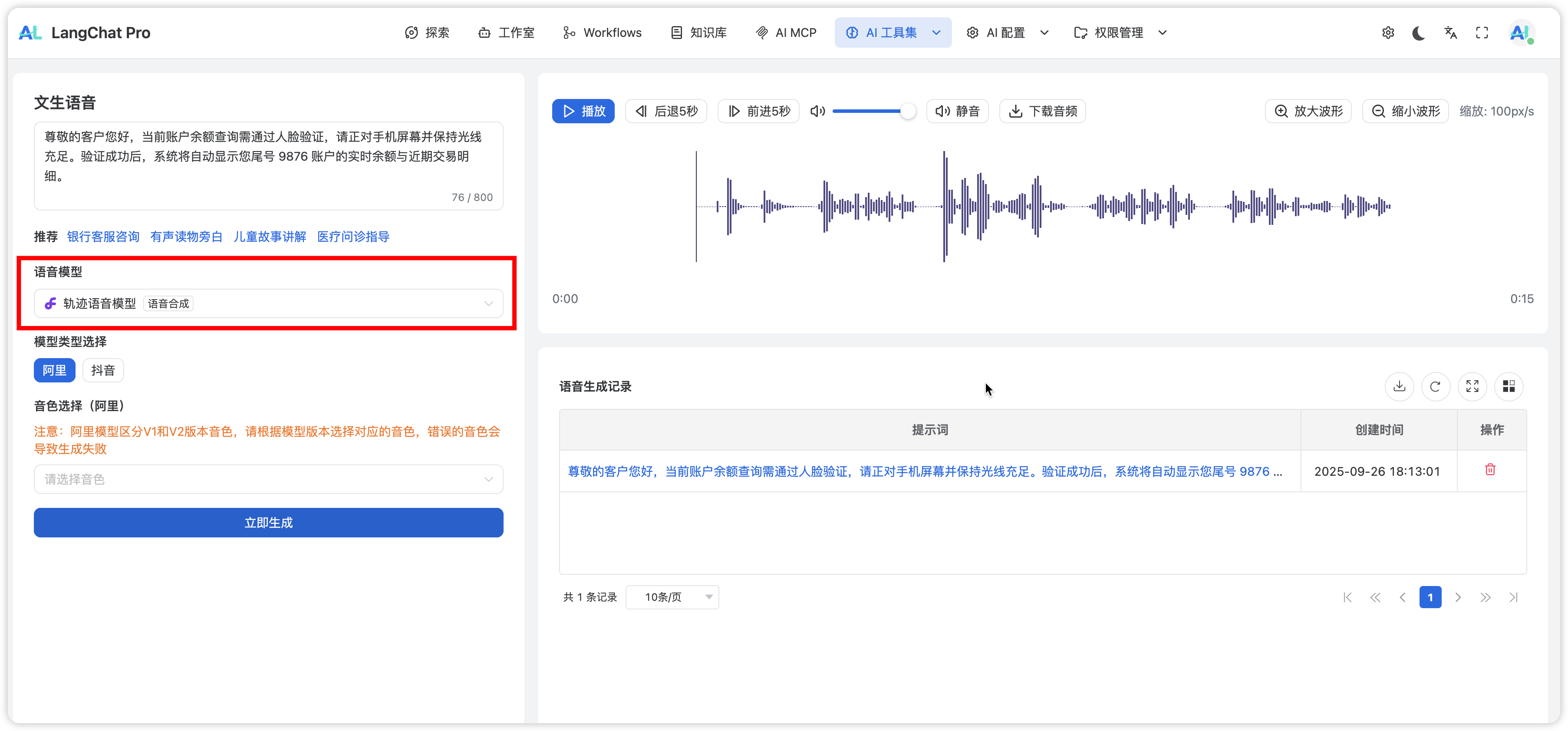
LangChat Pro 提供“语音合成”测试页面,用于快速验证不同模型供应商的 TTS 效果:- 用途:Prompt/音色模板迭代、不同模型对比
- 范围:仅测试合成效果,不进行生产业务流转
- 当前支持:阿里、豆包、Gitee、硅基流动等
fnlp/MOSS-TTSD-v0.5):
参数与音色
不同模型的音色与参数存在差异:- 音色(voice):部分模型必须指定(如阿里),否则调用失败
- 语速/音量/音高:模型对范围与默认值支持不同
- 采样率/编码:影响音质与文件大小(如 16kHz/24kHz,mp3/wav/ogg)
播放与格式
- 播放器:右侧内置播放器可预览音频,并显示动态波形
- 格式:建议使用浏览器广泛支持的编码(mp3/ogg);wav 体积较大但兼容性好
- 下载与归档:将合成参数与样例音频一并归档,便于复现
稳定性与质量
- 文本规范化:去除多余符号、统一标点,提高合成清晰度
- 分段合成:长文本建议分段,避免超时/截断
- 重试策略:网络抖动或限频时增加重试与退避
最佳实践
- 预置“音色模板”,为品牌声音选择标准音色
- 固定采样率与编码,确保在目标平台可播放
- 对比不同模型在同一文本与音色下的表现
- 失败时优先检查:音色是否必填、采样率是否受支持