
本页面为独立的功能模块,主要用于测试多模态视觉理解(Vision-Language)能力,包括图片理解、OCR、定位与多图推理等,不与其他业务模块耦合。
概述
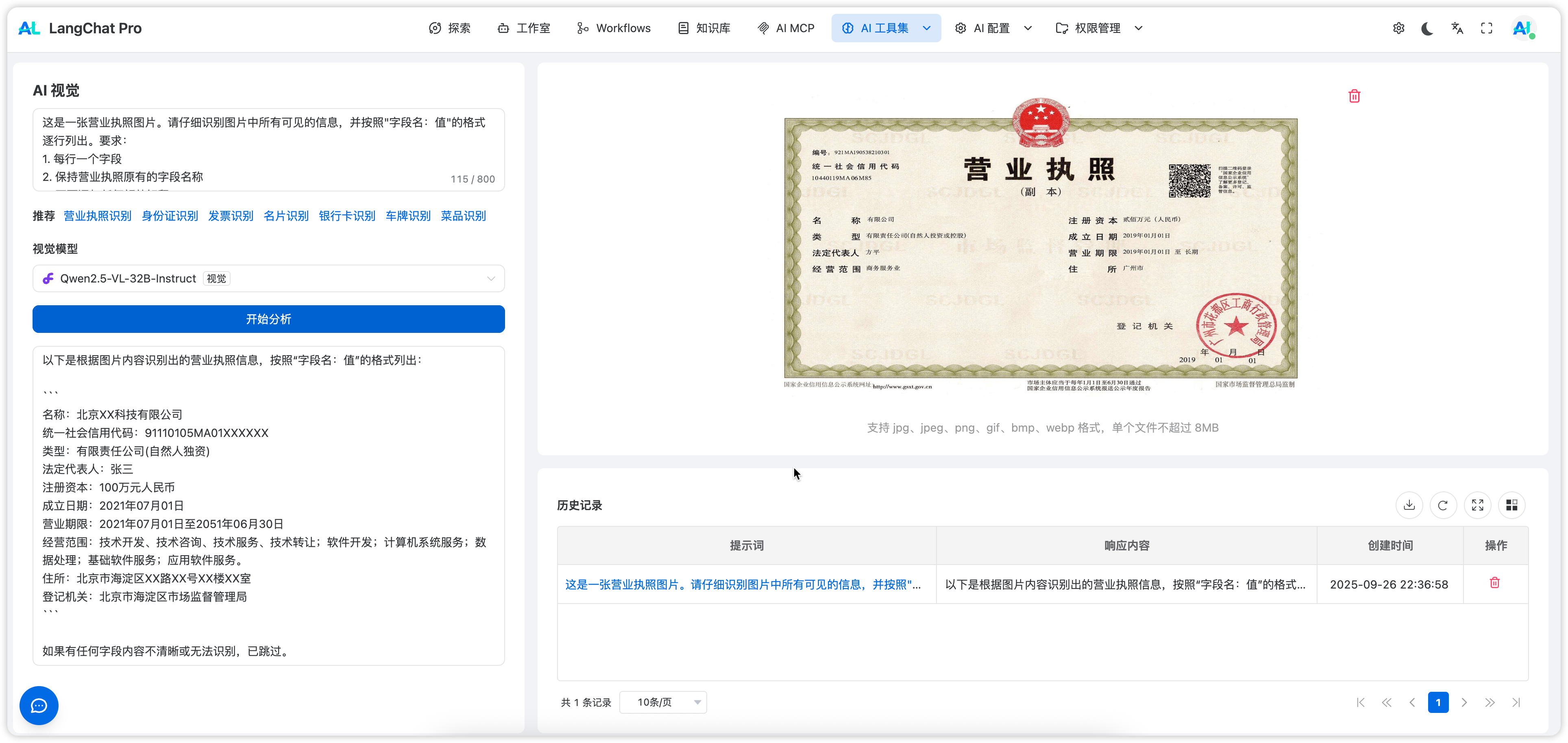
LangChat Pro 提供“AI 视觉”测试页面,便于验证不同模型对图片内容的理解能力:- 用途:Prompt 模板验证、模型效果对比、典型任务评估
- 范围:仅测试识别与描述能力,不进行生产业务编排
- 示例模型:阿里
Qwen2.5-VL-32B-Instruct
输入与规范
- 图片格式:建议使用
jpg/png,控制单图大小以提升响应速度 - 多图输入:部分模型支持多张图片同时推理(顺序与上下文相关)
- 文本约束:Prompt 明确任务目标(描述/回答/定位/对比)
- OCR 友好:文本清晰、背景干扰少更有利于识别
典型任务
- 通用描述:对图片内容进行自然语言描述
- 问答(VQA):就图片细节进行问答
- OCR 识别:识别图片中的文字、表格、票据等
- 目标定位:返回关键目标的位置或边界(取决于模型能力)
- 多图推理:对多张图片进行比较、归纳或步骤分析
数据与合规
- 隐私保护:避免上传包含个人隐私或敏感信息的图片
- 版权合规:确认图片来源合法授权
- 数据最小化:仅上传完成任务所必需的图片
最佳实践
- 任务要清晰:在 Prompt 中明确“期望输出格式/粒度/步骤”
- 图像要清楚:选择清晰、分辨率适中的图片,减少噪声
- 多图有顺序:上传顺序与描述一致,便于模型理解
- 失败先排查:格式、大小、模型是否支持该类型任务