
不同维度的向量数据无法兼容,要么使用输出维度相同的向量模型,要么创建新的知识库(生成新的向量表)
下列以 Pgvector 向量数据库为例,向量模型以 BAAI/bge-m3 为例
什么是向量维度?
在深入理解RAG向量维度之前,我们先通过一个简单的例子来理解”向量维度”的概念: 向量维度本质上是模型将文本转换成数字时使用的”特征空间大小”:- 512维:相当于将文本映射到512个特征维度上,每个维度代表文本的一个特征
- 1024维:相当于将文本映射到1024个特征维度上,可以捕捉更细粒度的语义信息
💡 类比理解:
- 想象你在描述一个人:
- 3维描述:身高、体重、年龄(基本信息)
- 10维描述:身高、体重、年龄、血型、星座、爱好、职业、学历、籍贯、婚姻状况(更详细)
- 1024维描述:数千个特征维度,包含极其丰富的语义信息
为什么不能跨维度查询数据?
这是最常见的问题:为什么不能用512维的向量去查询1024维的向量表?问题本质:维度不匹配
核心原因
-
向量空间不同:
- 512维向量和1024维向量处于完全不同的向量空间
- 它们在数学上是不可比的,就像2D平面和3D空间中的点无法直接比较
-
相似度计算失败:
- RAG查询的核心是计算向量之间的相似度(如余弦相似度)
- 相似度计算要求两个向量的维度完全相同
- 公式:
cos_sim = (A·B) / (|A| × |B|),其中A和B必须维度相同
- 语义对齐问题:
- 不同维度的模型,其每个维度代表的语义含义完全不同
- 512维模型的第1维和1024维模型的第1维可能代表完全不同的特征
- 强制比较会产生无意义的结果
实际后果
如果强行使用不同维度查询,会出现以下错误:正确做法
配置步骤详解
在LangChat Pro中配置RAG向量维度时,需要严格按照以下步骤执行,确保向量模型和向量数据库的维度完全一致。整体配置流程
步骤1: 确认向量模型输出维度
我们使用硅基流动的API为例,首先需要确认此向量模型的输出向量维度: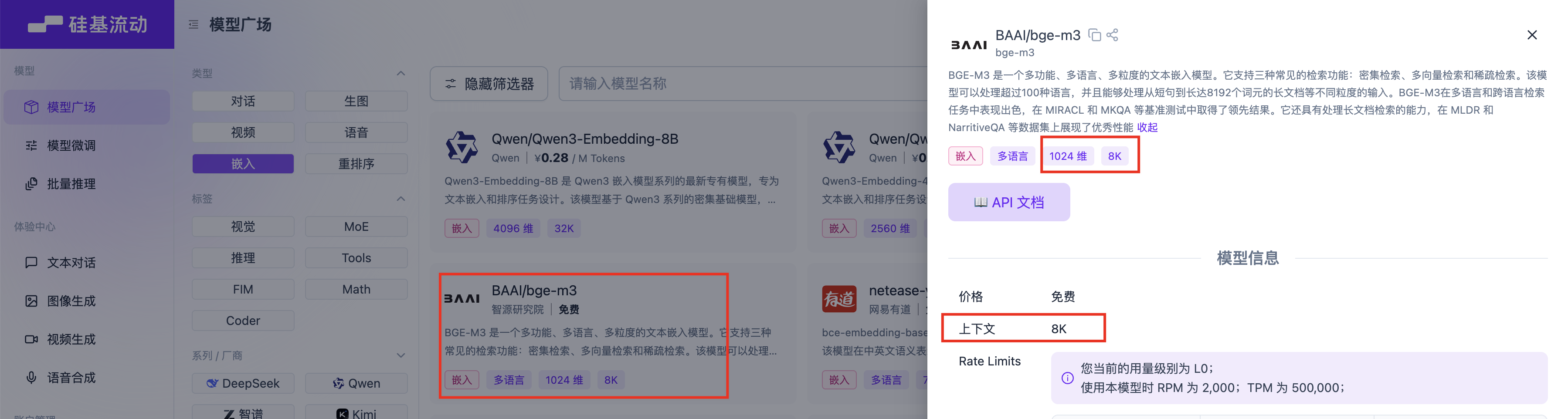 从模型文档中可以获取
从模型文档中可以获取 bge-m3 向量模型的关键信息:
| 参数 | 值 | 说明 |
|---|---|---|
| 向量维度 | 1024 | 输出向量的特征空间大小 |
| 上下文长度 | 8K (8192 tokens) | 单次可处理的文本长度 |
💡 提示:1024维度向量能够捕捉丰富的语义信息,8K上下文长度足以处理大部分文档分片场景。
步骤2: 在LangChat Pro配置向量模型
确认模型维度后,在LangChat Pro平台中配置这个模型: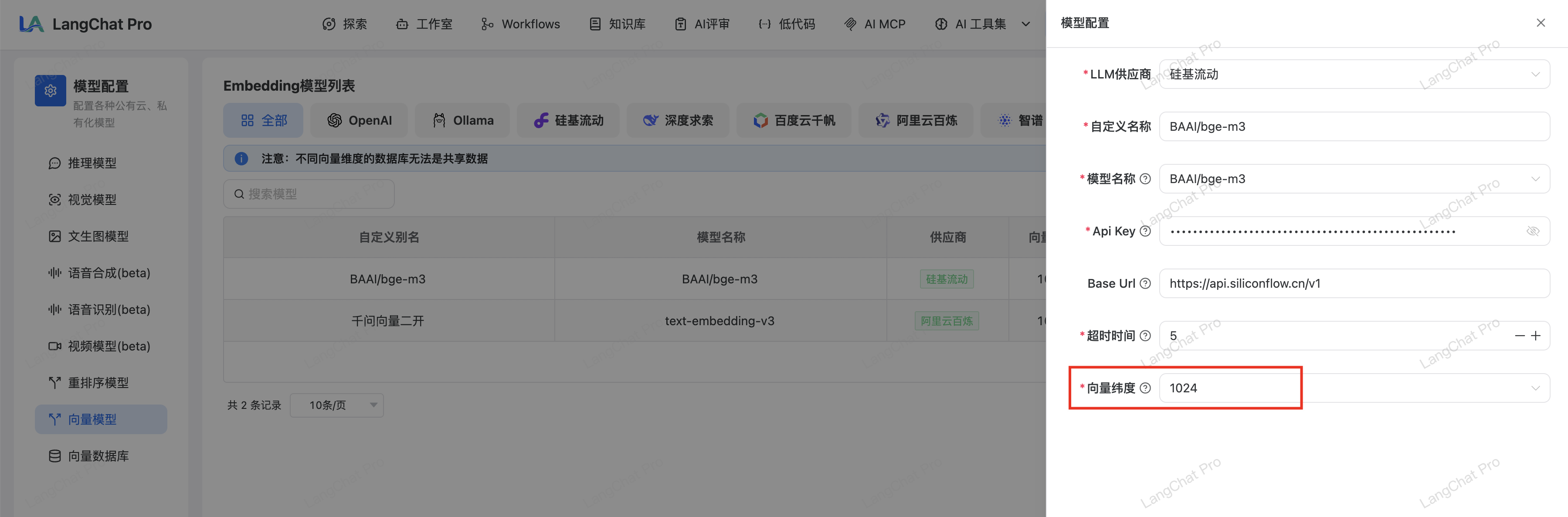 配置要点:
配置要点:
- 选择
1024作为向量维度(必须与模型输出维度一致) - 配置API密钥和端点地址
- 测试连接确保模型可用
步骤3: 配置向量数据库
准备好向量数据库(以Pgvector为例),然后新增配置: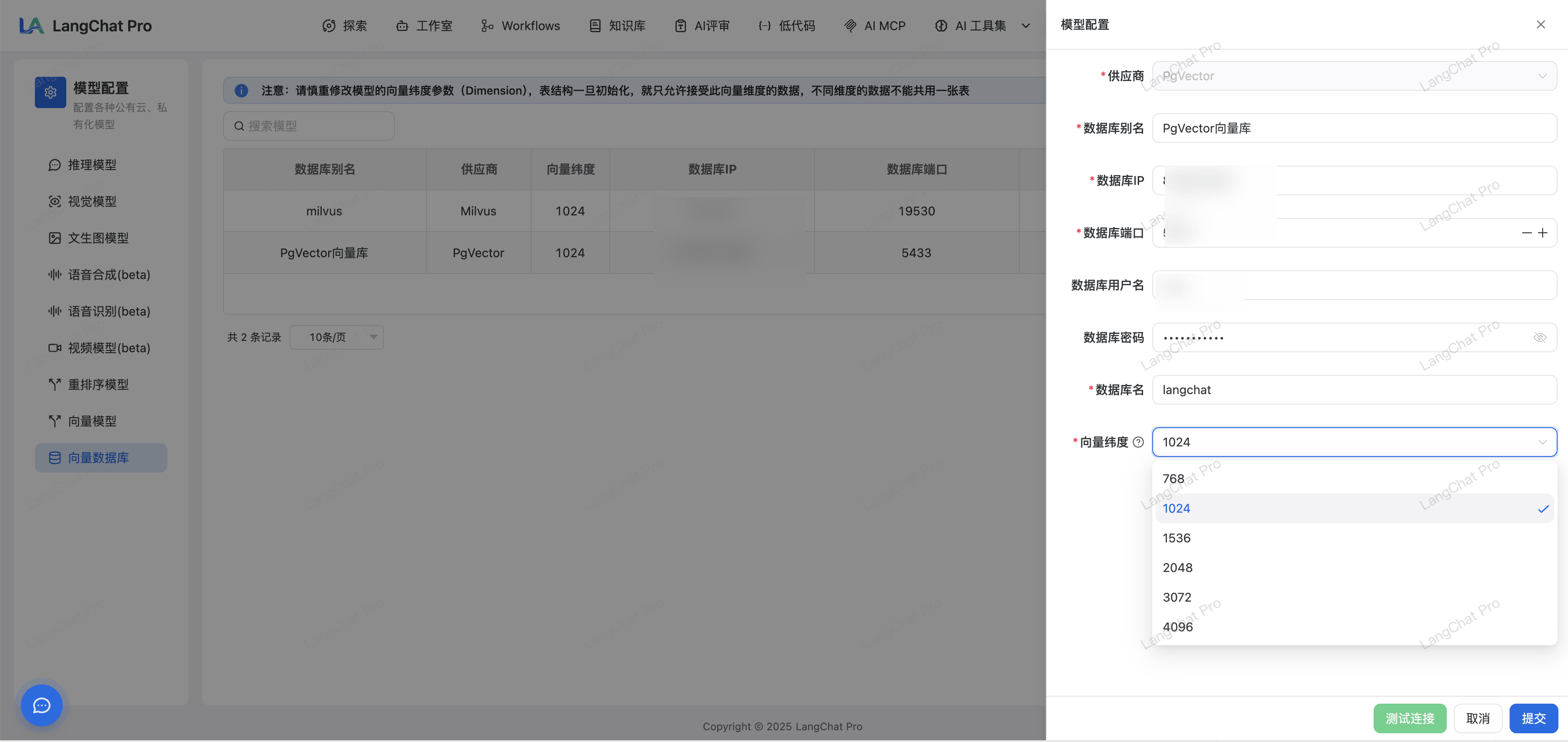 配置要点:
配置要点:
- 向量维度必须设置为
1024(与向量模型完全一致) - 配置数据库连接信息(host、port、database、username、password)
- 确保数据库权限正常
步骤4: 维度一致性验证
重要原则:- 向量模型和向量数据库的维度必须完全一致
- 一旦配置完成,不建议频繁切换不同的向量模型
- 不同维度之间完全不兼容,切换模型必须创建新知识库
RAG流程详解
知识库向量化完整流程
在LangChat Pro中,知识库的向量化过程分为两个阶段:元数据创建和向量表初始化。创建向量表的详细过程
在LangChat Pro产品中,新建知识库后,只是在MySQL中新增一条元数据记录,此时Pgvector并不会创建新表。 当第一次使用配置好的向量模型和向量数据库实例执行向量化时,才会初始化Pgvector的表结构并固定向量维度。向量表初始化时序图
核心配置代码解析
在langchain4j中,向量表的创建通过以下配置实现(在LangChat Pro产品中也能找到这段代码):配置参数说明
| 参数 | 说明 | 注意事项 |
|---|---|---|
| dimension | 向量维度(1024) | ⚠️ 一旦创建不可更改 |
| table | 表名(knowledgeId) | 每个知识库对应一张表 |
| createTable | 是否自动创建表 | 首次设置为true |
| dropTableFirst | 是否先删除表 | 始终设置为false,防止数据丢失 |
向量表结构
创建成功后,你可以在Pgvector数据库中看到对应的向量表: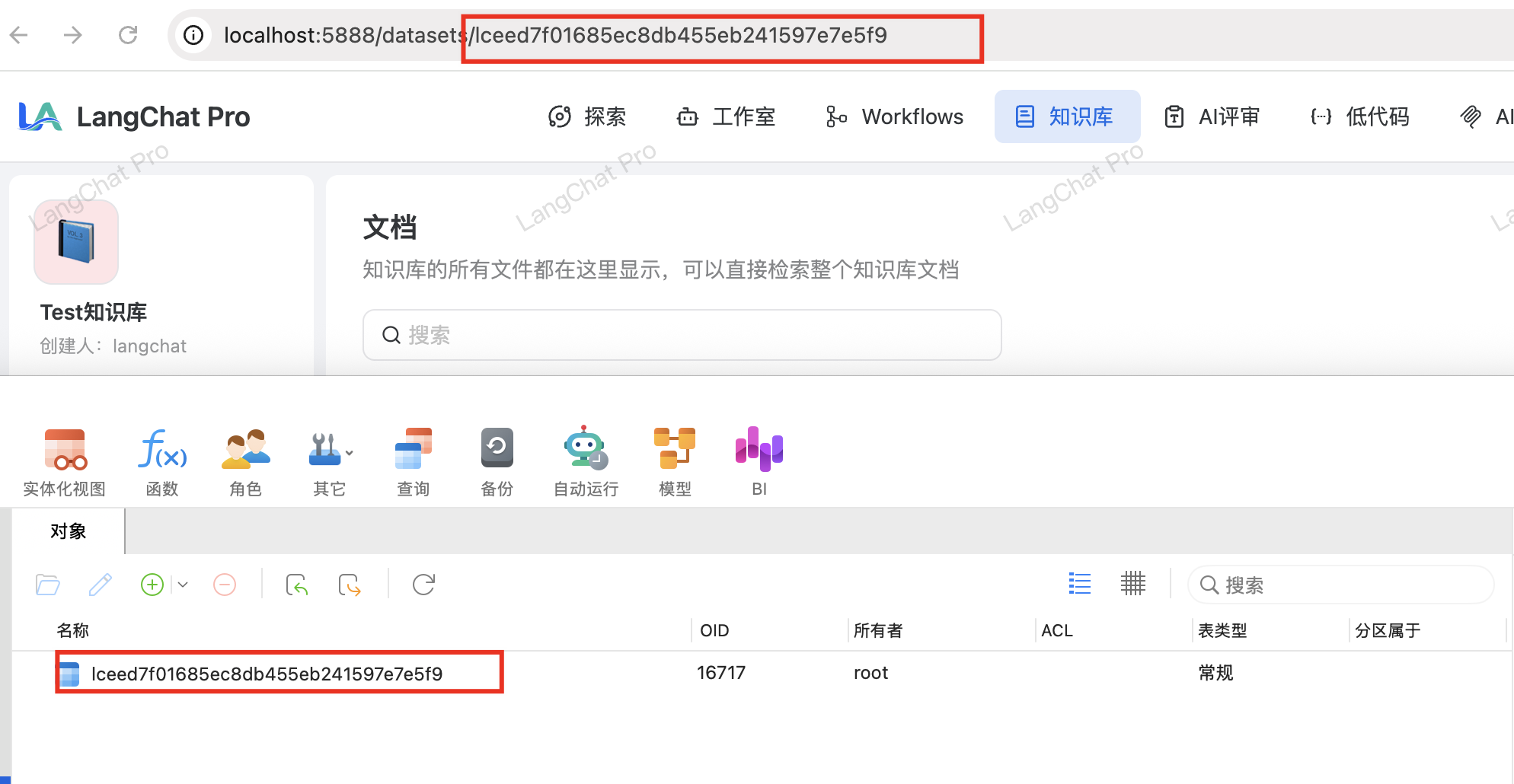 重要特性:
重要特性:
- 维度固定:
embedding列的维度在表创建时固定为1024 - 无法更改:一旦表创建,维度参数无法修改
- 独立存储:每个知识库有独立的向量表
- 索引优化:自动创建向量索引加速相似度查询
查询流程
总结与最佳实践
关键要点
-
向量维度不可更改:
- 向量表一旦创建,维度参数永久固定
- 切换不同维度的模型必须创建新知识库
-
维度必须一致:
- 向量模型输出维度 = 向量数据库配置维度
- 任何不匹配都会导致查询失败
-
表名与知识库绑定:
- 每个知识库对应一张独立的向量表
- 表名使用
knowledgeId唯一标识
常见错误及解决方案
| 错误现象 | 原因 | 解决方案 |
|---|---|---|
| dimension mismatch | 查询向量与表向量维度不同 | 检查模型和数据库配置是否一致 |
| table not found | 向量表未创建 | 上传文档执行向量化自动创建 |
| 向量查询无结果 | 维度配置错误导致数据未正确存储 | 重新配置并重建知识库 |
最佳实践建议
⚠️ 重要提醒:在生产环境中,建议在项目初期确定好向量模型,避免后期因维度不兼容而需要重建整个知识库。