文档处理是 RAG 系统的关键环节,涉及文档上传、智能分段、向量化解析等核心步骤,直接影响检索精度和回答质量。
文档管理功能
在 LangChat Pro 知识库中,文档管理提供三种核心功能:
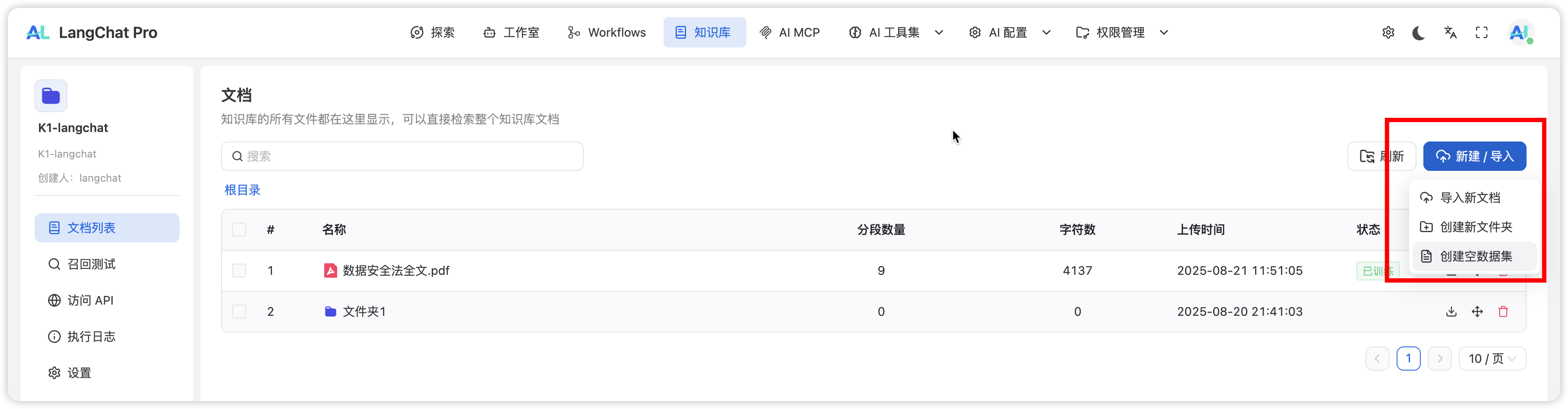
功能说明
| 功能 | 用途 | 适用场景 |
|---|
| 导入新文档 | 上传各类文档文件 | 知识库内容构建 |
| 创建新文件夹 | 组织文档结构 | 分类管理文档 |
| 创建空数据集 | 结构化数据录入 | 表格、问答对等 |
建议根据业务需求合理组织文档结构,便于后续检索和管理。
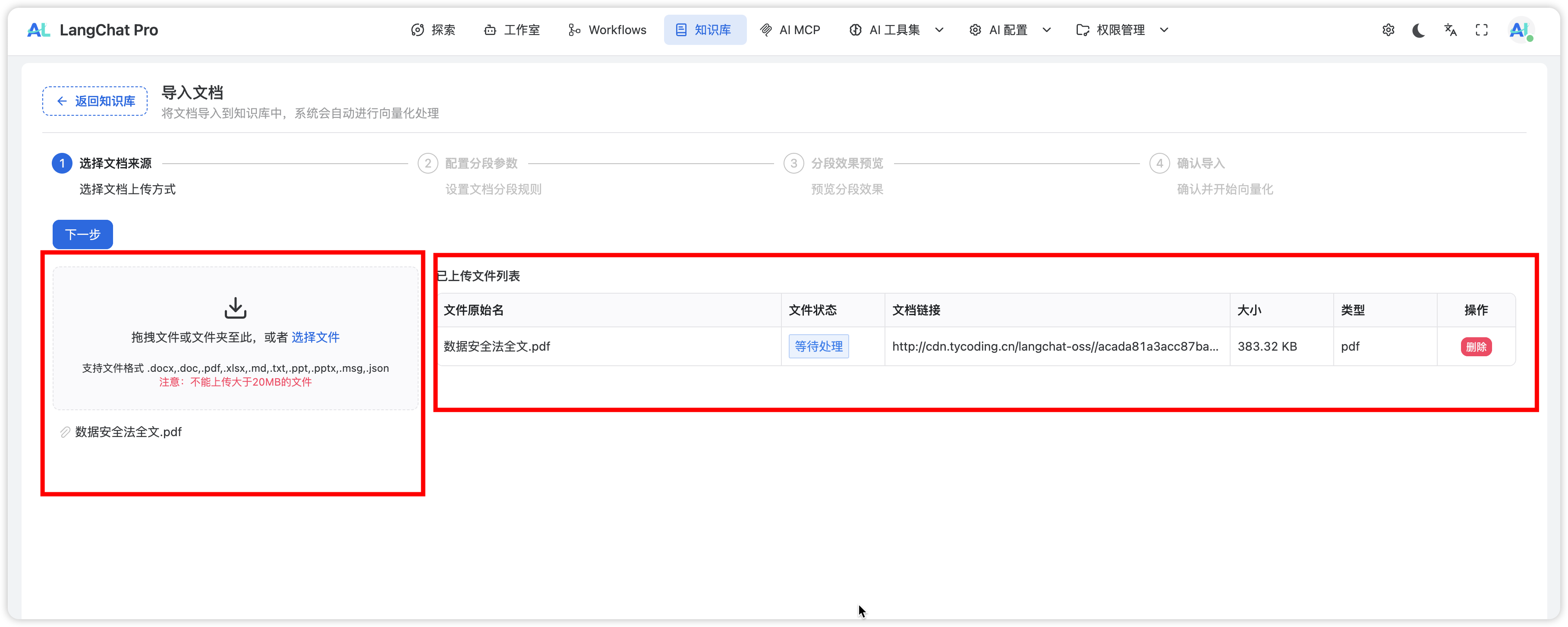
导入新文档
支持的文件格式
| 文件类型 | 扩展名 | 处理方式 |
|---|
| Office 文档 | .docx, .doc, .ppt, .pptx | 结构化文本提取 |
| PDF 文档 | .pdf | 文本提取 + OCR |
| 表格文件 | .xlsx | 结构化表格解析 |
| 文本文件 | .md, .txt | 直接文本处理 |
| 邮件文件 | .msg | 邮件内容提取 |
| 数据文件 | .json | JSON 结构化解析 |
文件限制
- 大小限制:单文件不超过 20MB
- 批量上传:支持多文件同时上传
- 拖拽上传:支持拖拽文件到上传区域
文件大小限制主要考虑:
- 服务器性能:避免内存溢出
- 向量化效率:大文件分段处理耗时
- 检索精度:过大的文本段影响语义匹配
上传结果
导入成功后,系统显示文档处理状态:
常见问题排查
上传失败
- 检查 OSS 配置:确认对象存储服务配置正确
- 查看服务日志:排查具体的错误信息
- 网络连接:确认网络环境稳定
批量上传注意事项
- 控制并发数量,避免服务器压力过大
- 分批处理大量文件,提高成功率
- 监控系统资源使用情况
文件大小限制说明
- 前端限制:防止用户上传过大文件
- 后端处理:确保向量化过程稳定
- 性能优化:平衡处理速度与质量
配置分段参数
文本分段是 RAG 系统的核心技术,直接影响检索精度和回答质量。合理的分段策略能够:
分段模式选择
MinerU模式请查看单独的介绍页面:MinerU
1. 智能解析模式(推荐)
系统根据文档类型自动选择最优分段策略:
| 文档类型 | 分段策略 | 优势 |
|---|
| Excel/CSV | 按行分段 | 保持数据完整性 |
| PDF/Word | 按句子分段 | 维持语义连贯性 |
| 技术文档 | 按段落分段 | 保持逻辑结构 |
| 其他类型 | 默认策略 | 通用适配 |
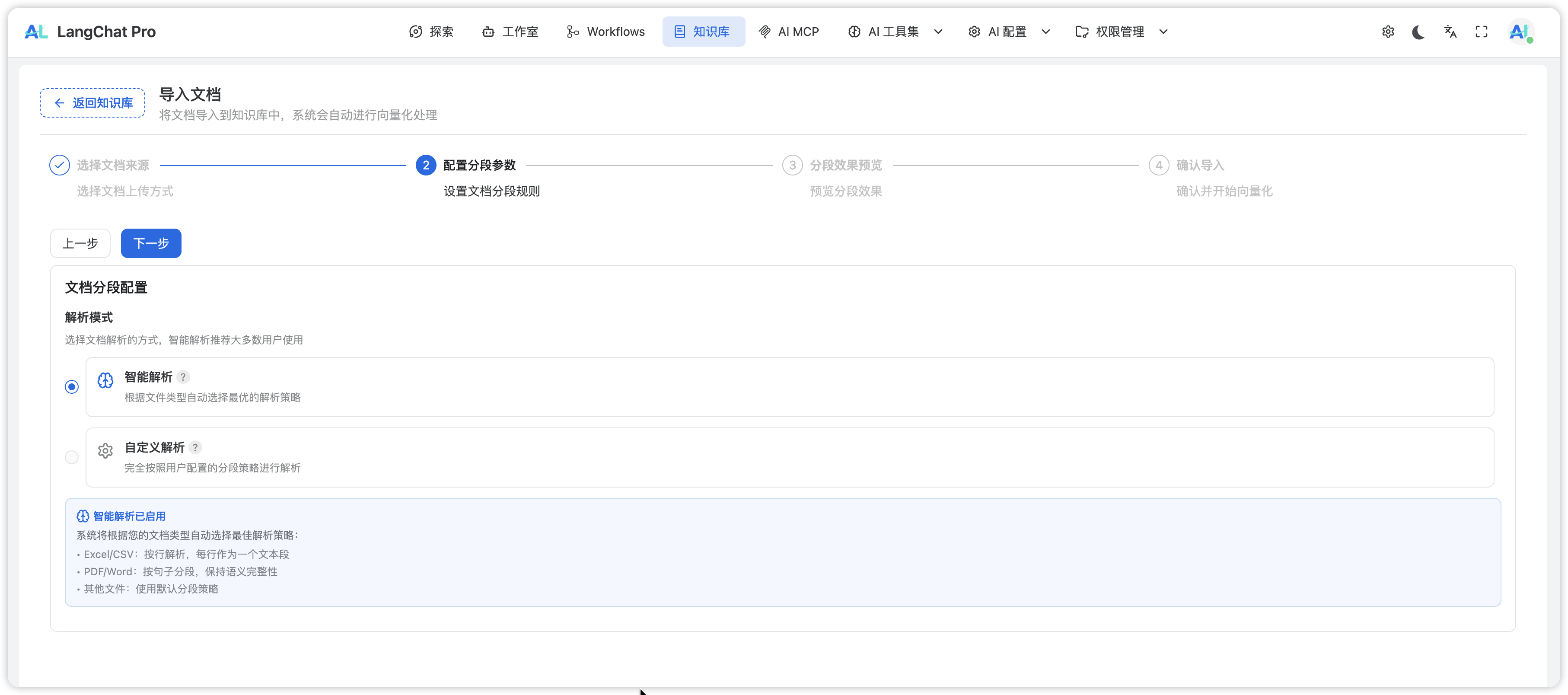
智能解析模式适用于大多数场景,系统已针对不同文档类型进行了优化,建议优先使用。
2. 自定义解析模式
支持高级用户根据特殊需求配置分段策略:
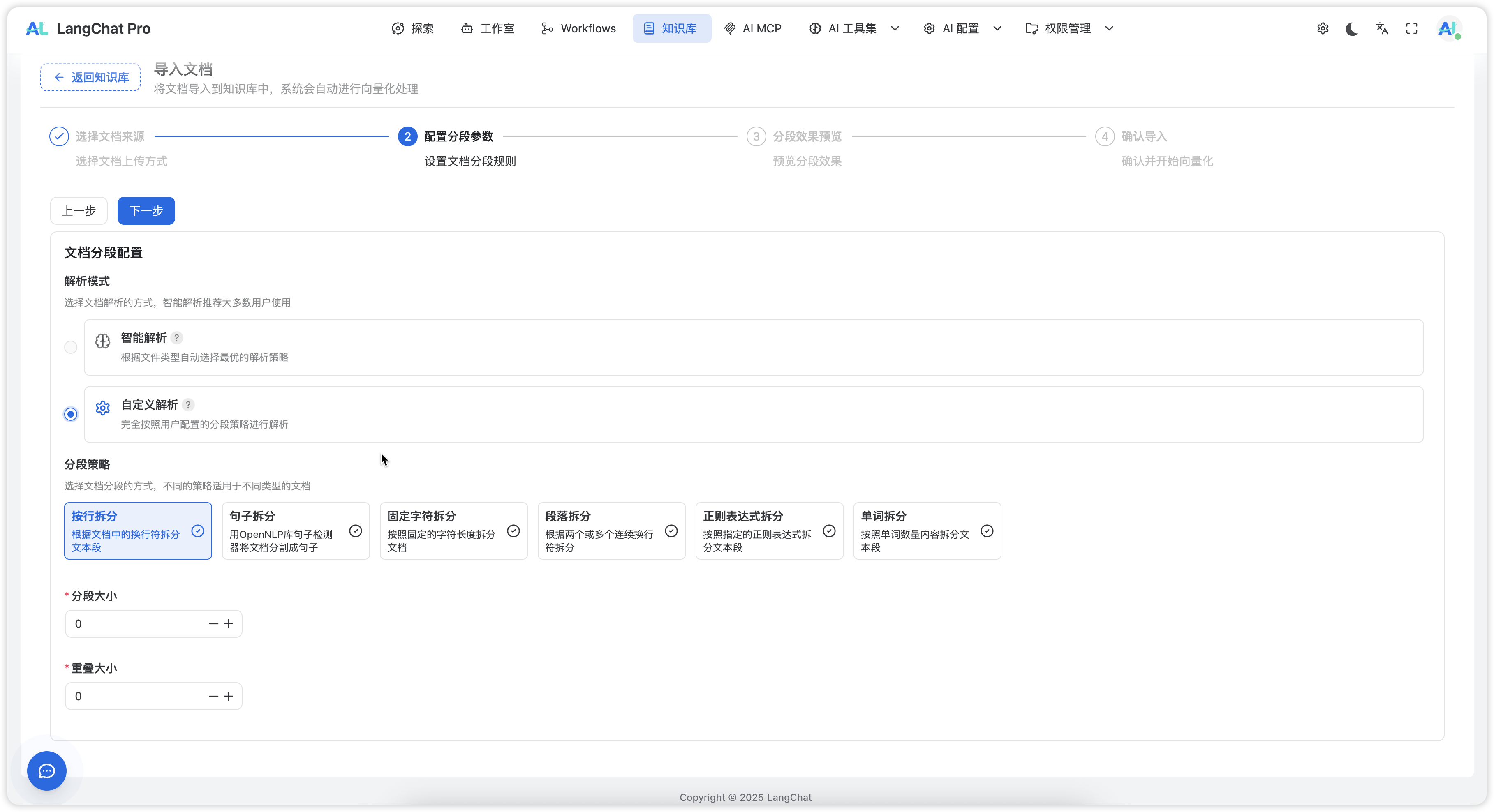
分段策略详解
| 策略类型 | 分割依据 | 适用场景 | 优势 | 劣势 |
|---|
| 按行拆分 | 换行符 | 结构化数据 | 简单快速 | 可能破坏语义 |
| 句子拆分 | 句子边界 | 自然语言文本 | 语义完整 | 句子长度不均 |
| 固定字符拆分 | 字符数量 | 均匀分割 | 长度一致 | 可能截断语义 |
| 段落拆分 | 段落边界 | 文档结构 | 逻辑完整 | 段落大小差异大 |
| 正则表达式 | 自定义模式 | 特殊格式 | 高度灵活 | 配置复杂 |
| 单词拆分 | 单词数量 | 英文文档 | 语义友好 | 中文效果一般 |
核心参数配置
分段大小 (Chunk Size)
- 定义:每个文本段的最大字符数
- 推荐值:200-800 字符
- 影响:
- 过小:信息碎片化,上下文不足
- 过大:检索精度下降,计算成本高
重叠大小 (Overlap Size)
- 定义:相邻文本段之间的重叠字符数
- 推荐值:20-100 字符
- 作用:
- 保持上下文连续性
- 避免关键信息被分割
- 提高检索召回率
分段参数影响分析
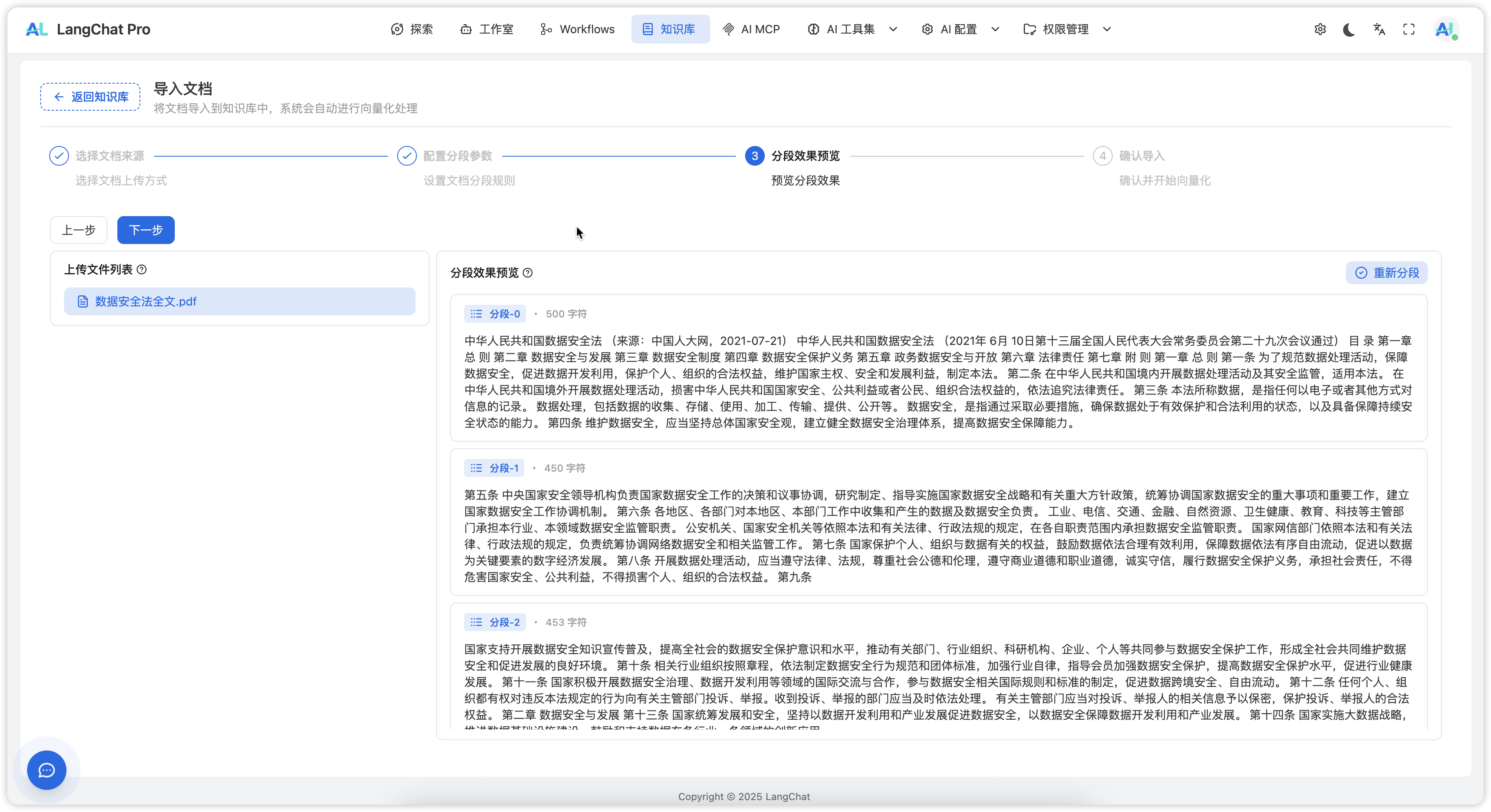
分段预览
配置分段参数后,可预览分段效果以验证配置合理性:
为什么要进行文本分段?
1. 语义完整性
- 保持上下文:确保每个文本段包含完整的语义信息
- 避免截断:防止重要信息被意外分割
- 逻辑连贯:维持文档的逻辑结构
2. 检索精度优化
- 精确匹配:较小的文本段提高检索精确度
- 减少噪声:避免无关信息干扰检索结果
- 相关性提升:提高检索结果与查询的相关性
3. 计算效率
- 向量维度:控制向量化处理的复杂度
- 检索速度:优化向量相似度计算性能
- 存储优化:平衡存储成本与检索效果
分段质量评估
预览要点
在分段预览中,重点关注:
- 语义完整性:每个分段是否包含完整信息
- 长度分布:分段长度是否合理均匀
- 重叠效果:相邻分段的重叠是否恰当
- 边界处理:分段边界是否自然合理
确认导入
确认导入后,系统将执行完整的向量化处理流程:
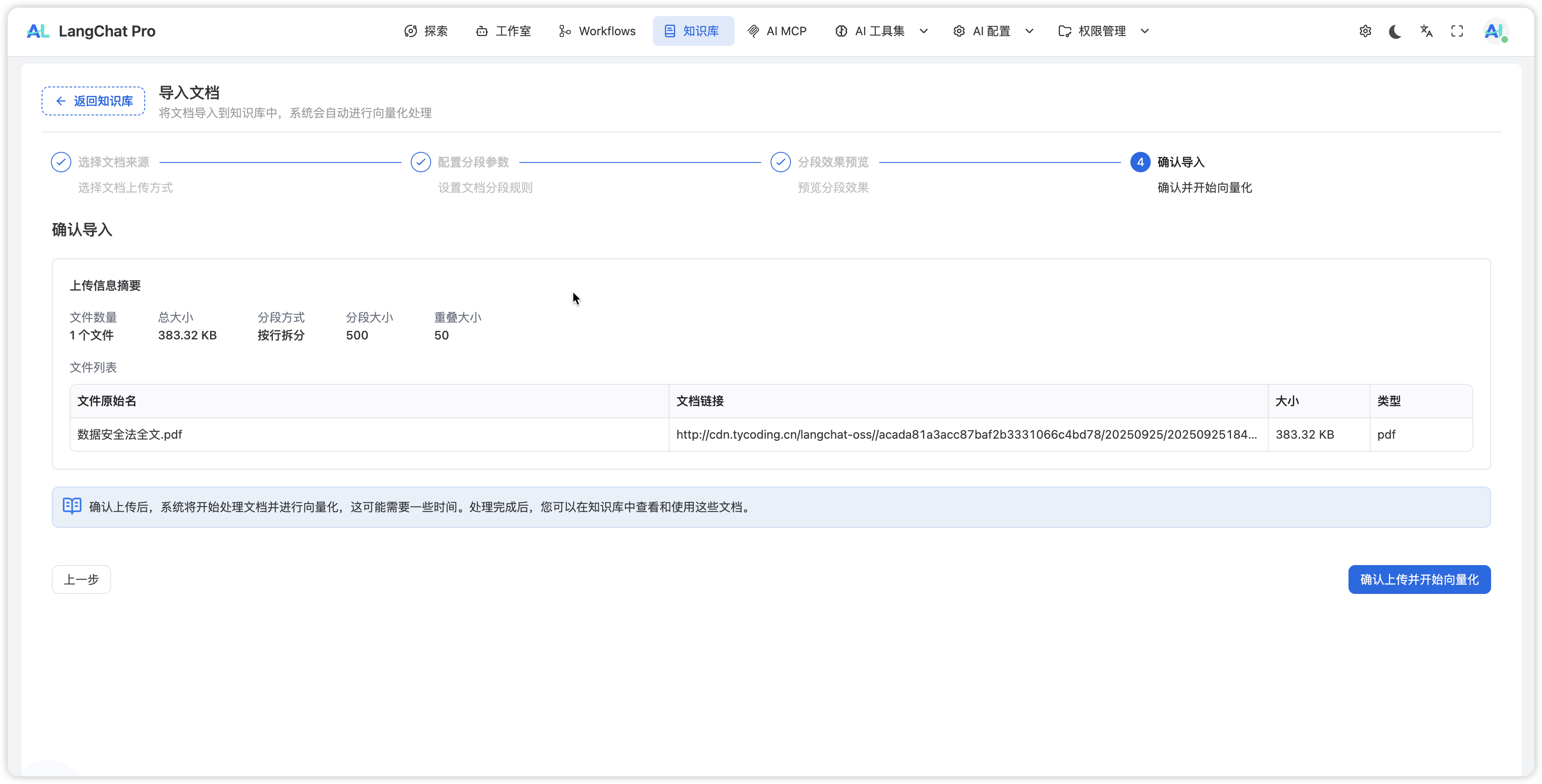
向量化处理
高维向量概念
向量化是将文本转换为高维数值向量的过程,每个文本段被映射到多维空间中的一个点:
- 维度数量:通常为 384、512、768、1024 等
- 数值范围:向量中每个元素通常是浮点数
- 语义表示:相似语义的文本在向量空间中距离较近
向量化流程
检索实现原理
1. 相似度计算
- 余弦相似度:计算向量间夹角的余弦值
- 欧几里得距离:计算向量间的直线距离
- 点积相似度:计算向量的内积
2. 检索过程
- 查询向量化:将用户查询转换为向量
- 相似度搜索:在向量空间中查找最相似的文档片段
- 结果排序:按相似度分数对结果进行排序
- 返回结果:返回最相关的文档片段
向量质量影响因素
| 因素 | 影响 | 优化建议 |
|---|
| 模型质量 | 向量表示能力 | 选择高质量的 Embedding 模型 |
| 文本质量 | 语义清晰度 | 确保文本分段质量 |
| 分段策略 | 语义完整性 | 合理配置分段参数 |
| 预处理 | 噪声过滤 | 清理无关字符和格式 |
向量化质量直接影响检索效果,建议选择适合业务场景的 Embedding 模型和分段策略。
RAG 准确性优化
文本分段对准确性的影响
文本分段是影响 RAG 系统准确性的关键因素之一:
1. 分段大小的影响
2. 分段边界的重要性
- 语义边界:在自然语义边界处分割
- 逻辑边界:保持逻辑结构的完整性
- 上下文边界:确保上下文信息不丢失
最佳实践建议
1. 分段策略优化
| 文档类型 | 推荐策略 | 分段大小 | 重叠大小 |
|---|
| 技术文档 | 按段落分割 | 400-600 字符 | 50-80 字符 |
| 问答对 | 按问答分割 | 200-400 字符 | 20-50 字符 |
| 长篇文章 | 按章节分割 | 600-800 字符 | 80-100 字符 |
| 表格数据 | 按行分割 | 100-300 字符 | 10-30 字符 |
2. 质量控制措施
- 语义完整性检查:确保每个分段包含完整语义
- 边界合理性验证:避免在句子中间分割
- 重叠有效性评估:确保重叠部分有意义
- 长度分布分析:保持分段长度相对均匀
3. 持续优化流程
分段质量保证
1. 完整性原则
- 确保关键信息不被分割
- 保持语义单元完整
- 维持逻辑结构连贯
2. 一致性原则
- 统一的分段标准
- 相似文档使用相同策略
- 保持处理流程一致
3. 可扩展性原则
分段质量直接影响 RAG 系统性能,建议在生产环境部署前进行充分的测试和优化。