
知识库是 RAG(检索增强生成)系统的核心组件,负责将非结构化文档转换为可检索的向量表示,为 AI 模型提供准确的上下文信息。
RAG 系统架构
知识库在 RAG 系统中承担文档存储与检索的关键角色:文档处理能力
LangChat Pro 知识库支持多种文档格式的智能解析:支持的文档类型
| 文档类型 | 处理方式 | 输出格式 |
|---|---|---|
| Office 文档 | Word、PowerPoint、Excel | 结构化文本 |
| PDF 文档 | 文本提取 + OCR | 纯文本 |
| 图片文件 | PaddleOCR 识别 | 文本内容 |
| Excel 表格 | 结构化解析 | Table 格式文本 |
| 纯文本 | 直接处理 | 原始文本 |
处理流程
创建知识库
在 LangChat Pro 的「知识库」页面统一管理所有知识库资源: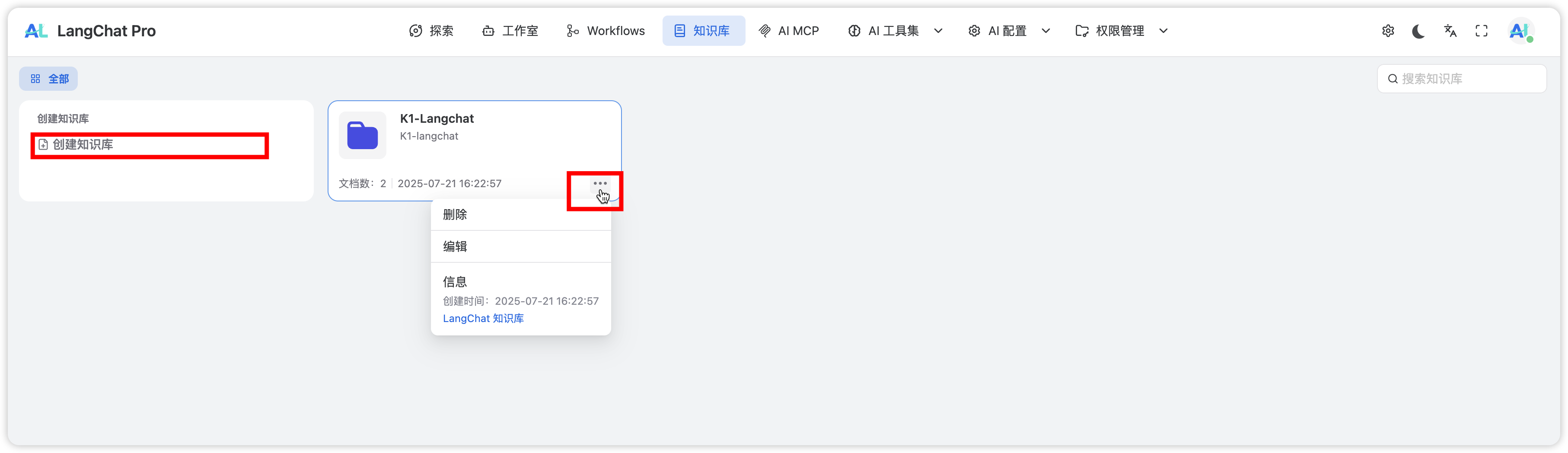
前置配置要求
创建知识库前需完成以下基础设施配置:1. 对象存储服务 (OSS)
- 用途:存储原始文档文件
- 要求:必须配置 OSS 服务用于文件上传
- 配置路径:AI 配置 -> 文件存储配置
2. 向量数据库
- 用途:存储文档向量表示
- 支持类型:Redis、PgVector、Milvus、Elasticsearch
- 配置路径:AI 配置 -> 模型配置 -> 向量数据库
3. 向量模型 (Embedding)
- 用途:将文本转换为高维向量
- 要求:已配置 Embedding 模型
- 配置路径:AI 配置 -> 模型配置 -> 向量模型
4. 重排序模型 (Rerank) - 可选
- 用途:对检索结果进行二次排序
- 优势:提升检索精度
- 配置路径:AI 配置 -> 模型配置 -> 重排序模型

检索配置
完成基础配置后,可调整检索参数以优化 RAG 性能: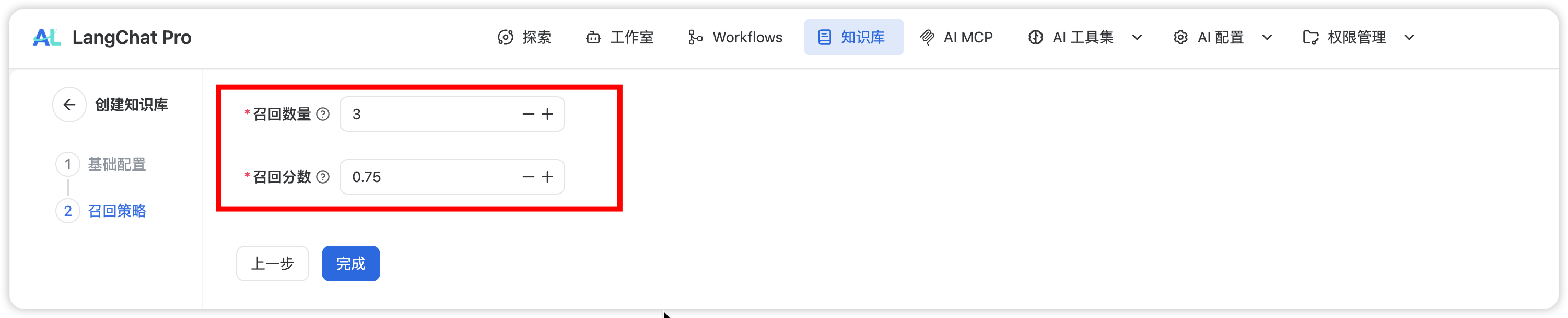
核心参数说明
召回数量 (Top-K)
- 定义:从向量数据库返回的相关文档片段数量
- 范围:通常设置为 5-20
- 影响:
- 数值过小:可能遗漏相关信息
- 数值过大:增加计算成本,可能引入噪声
相似度阈值 (Score Threshold)
- 定义:文档片段与查询的最小相似度分数
- 范围:0.0 - 1.0
- 影响:
- 阈值过高:检索结果过少,可能无法回答问题
- 阈值过低:检索结果过多,可能包含不相关信息
RAG 检索流程
参数调优建议
| 场景 | Top-K | 阈值 | 说明 |
|---|---|---|---|
| 精确问答 | 5-10 | 0.7-0.8 | 高精度,少噪声 |
| 开放对话 | 10-15 | 0.6-0.7 | 平衡精度与覆盖 |
| 探索性查询 | 15-20 | 0.5-0.6 | 更多信息,容忍噪声 |
参数调优需要根据实际业务场景和文档特点进行测试优化,建议从默认值开始逐步调整。