文档处理是 RAG 系统的关键环节,涉及文档上传、智能分段、向量化解析等核心步骤,直接影响检索精度和回答质量。
MinerU 解析
LangChat Pro是一个Java生态的解决方案,而文档文件的读取主要依赖于Java下的 Apache Tika。 但是实际上,Tika的解析能力非常有限,例如PDF中的Table就可能无法解析,因此,我们提供了外部服务的接入,快速做到将文档文件解析为结构化Markdown文本。1. 部署MinerU服务
官网地址:https://mineru.net/ RapidDoc 是一个轻量级、专注于文档解析的开源框架,支持 OCR、版面分析、公式识别、表格识别和阅读顺序恢复 等多种功能。 框架基于 Mineru 二次开发,移除 VLM,专注于 Pipeline 产线下的高效文档解析,在 CPU 上也能保持不错的解析速度。 本项目所使用的核心模型主要来源于 PaddleOCR 的 PP-StructureV3 系列(OCR、版面分析、公式识别、阅读顺序恢复,以及部分表格识别模型),并已全部转换为 ONNX 格式,支持在 CPU/GPU 上高效推理。在项目源码的根目录
docs/docker/rapid-doc 文件夹找到docker-compose脚本,一键启动即可。
RapidDoc(MinerU)解析流程
MarkdownSectionSplitter使用commonmark-java解析Markdown为AST(抽象语法树),确保准确识别文档结构和正确处理嵌套元素。通过自定义的节点渲染逻辑和上下文管理,实现了对各种Markdown元素的精确处理。 在LangChat Pro中,MarkdownSectionSplitter与MinerU/RapidDoc解析流程无缝衔接,形成了完整的文档处理解决方案:- Gotenberg服务将Office文档转换为高精度PDF
- MinerU/RapidDoc将PDF解析为Markdown格式
- MarkdownSectionSplitter对解析结果进行智能分段
- 分段后的内容用于向量化解析和知识库构建
2. 配置MinerU服务
需要修改后端配置文件application-dev.yml ,找到MinerU的配置并修改域名即可。
3. 分段选择MinerU解析
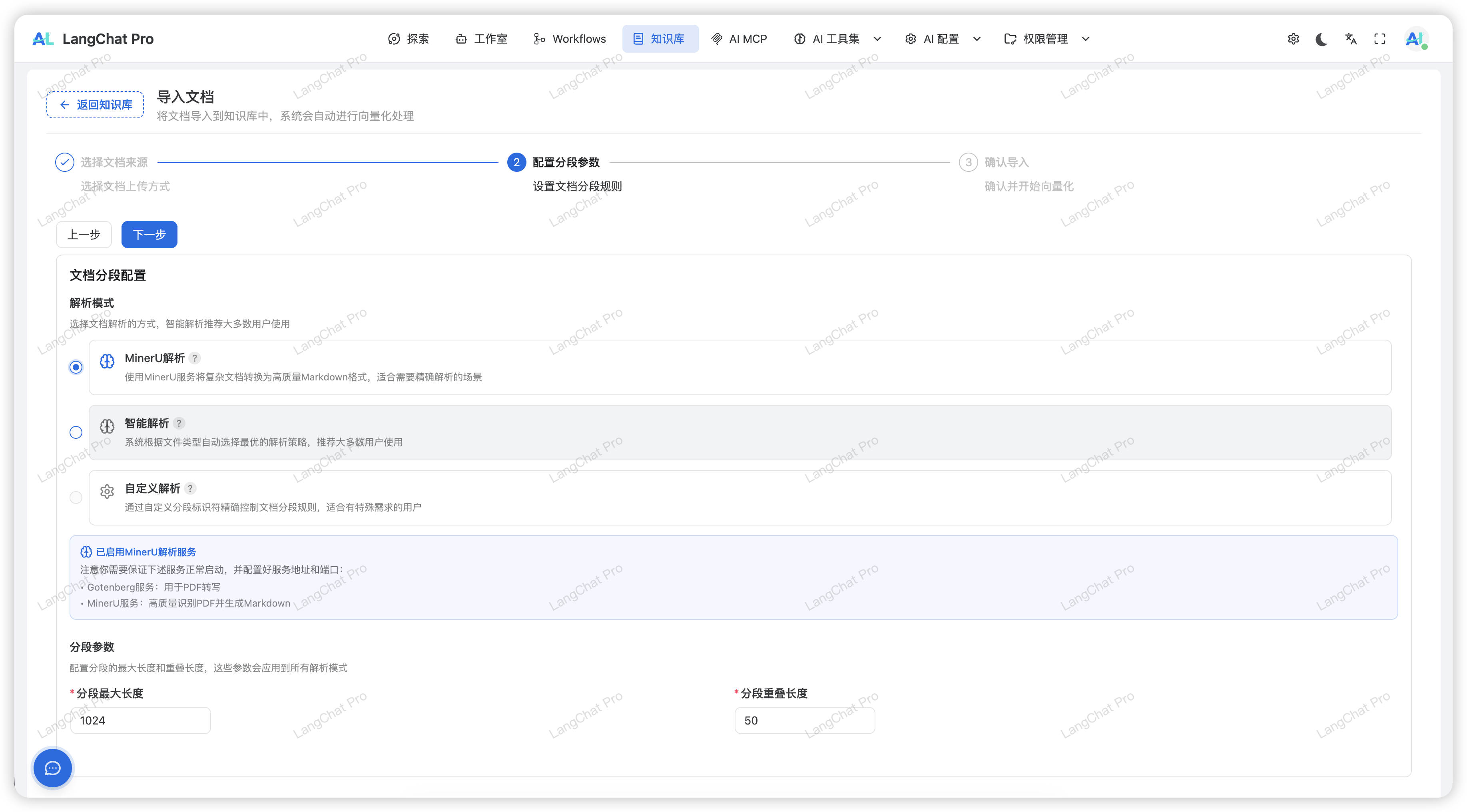 解析效果:
解析效果: