
文档解析节点是LangChat Pro工作流中的工具型节点,解析链接中的文档(不可解析网页),返回解析后的文档文本内容,将解析结果作为变量传递给下游节点。
节点特性
文档解析节点属于工具型处理节点,其核心特性是执行文档解析操作并将结果封装为上下文变量,而非直接输出给用户。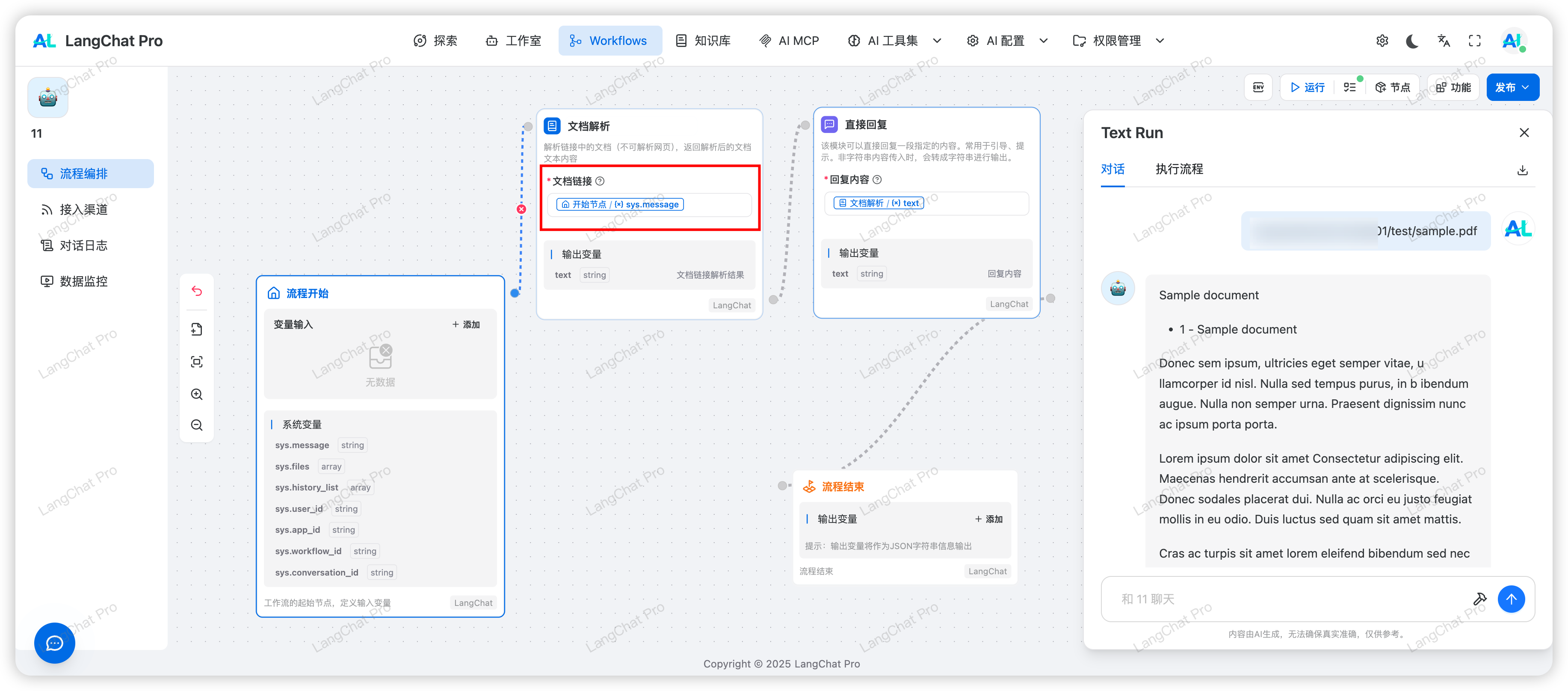 此节点主要是将文档文件的链接解析为文本内容,他经历了几个步骤:
此节点主要是将文档文件的链接解析为文本内容,他经历了几个步骤:
- 根据URL链接下载文件到本地Cache
- 读取文件内容
- 使用Tika解析文件内容并返回
工具节点 vs 输出节点
在LangChat Pro工作流中,节点按照输出特性分为两类: 输出节点(直接响应用户):- LLM大模型节点:支持流式输出
- 直接回复节点:输出变量内容
- 文档解析节点
- 百度搜索节点
- 知识库检索节点
- 其他功能节点
执行场景对比
文档解析节点
文档解析节点专门用于解析文档链接,支持多种文档格式的解析和文本提取。配置参数
输入参数
文档链接:- 支持动态引用流程上下文变量
- 支持静态文档链接输入
- 支持变量和链接的混合输入
- 通过智能变量选择器配置
- 待解析的文档链接地址
支持解析的文档类型
文档格式:- PDF文档
- Word文档(.doc, .docx)
- Excel文档(.xlsx)
- PowerPoint文档(.pptx)
- 文本文件(.txt)
- 其他常见文档格式
- 仅支持文档链接解析
- 不支持网页内容解析
- 需要文档可公开访问
输出变量
文档链接解析结果:- 数据类型:TEXT文本格式
- 内容:从文档中提取的文本内容
- 用途:供下游节点引用和处理
典型使用场景
场景一:简单文档解析
适用场景:- 用户上传文档的内容解析
- 简单的文档内容展示
- 文档信息的自动提取
场景二:文档+AI分析
适用场景:- 需要AI分析文档内容
- 智能化的文档处理
- 结合文档和AI的内容分析
场景三:多文档对比分析
适用场景:- 多文档的内容对比
- 文档差异分析
- 批量文档处理
场景四:文档内容提取
适用场景:- 从结构化文档中提取特定信息
- 文档数据的格式化处理
- 关键信息的自动提取
场景五:文档内容存储
适用场景:- 文档内容的数据库存储
- 文档信息的持久化
- 文档管理系统的集成
文档解析节点是工作流中文档处理的重要工具,专门用于解析文档链接并提取文本内容。通过合理配置文档链接,可以实现高效的文档内容提取和处理,为后续的AI分析、数据存储等操作提供数据基础。